Оглавление
1. Инструкция по использованию Parallel
8. Удалённое выполнение
9. Режим Pipe (передача данных по трубе)
10. Прочие функции
11. Примеры
1. Инструкция по использованию Parallel
Что такое GNU Parallel
GNU parallel — это инструмент оболочки для параллельного выполнения работ используя один или более компьютер.
В качестве работы может быть единичная команда или небольшой скрипт, который должен быть запущен для каждой строки из полученного ввода. Типичным вводом является список файлов, список хостов, список пользователей, список URL, список таблиц. В качестве работы может быть команда, которая считывает по трубе (pipe). GNU parallel затем может разбить ввод на блоки и передать блоки по трубе параллельно в каждую команду.
GNU parallel может заменить вам программы xargs и tee. А также не только заменить циклы (loops), но и сделать их выполнение более быстрым за счёт параллельного выполнения нескольких работ.
У программы много опцией, в том числе для контролирования ввода и вывода. Также программа может контролировать запуск новых работ в зависимости от доступных системных ресурсов (свободная оперативная память и загруженность центрального процессора).
Как установить GNU Parallel
Parallel присутствует в стандартных репозиториях популярных дистрибутивов Linux.
Для установки в Debain, Linux Mint, Ubuntu, Kali Linux и их производных выполните:
sudo apt install parallel
Для установки в Arch Linux, BlackArch и их производных выполните:
sudo pacman -S parallel
2. Основы Parallel
Файлы для тестовых запусков программ
Чтобы показывать работу программы на конкретных примерах, которые вы можете повторять, выполните следующую команду:
# Если в вашей системе отсутствует программа 'seq',
# то замените в последующей команде 'seq' на 'jot'
seq 5 | parallel seq {} '>' example.{}
В результате будет создано пять файлов вида example.1..5.
Синтаксис запуска Parallel
При получении аргументов из стандартного ввода команда запускается так:
parallel [опции] [команда [аргументы]] < список_аргументов
При указании аргументов в строке команды:
parallel [опции] [команда [аргументы]] ( ::: аргументы | :::+ аргументы | :::: файл(ы)_с_аргументами | ::::+ файл(ы)_с_аргументами ) ...
Источники ввода
Поскольку по своей функции программа Parallel подразумевает, что ею будет запущено несколько экземпляров другой программы, то при запуске нужно указать ту другую программу и аргументы к ней, пример простого случая запуска Parallel:
parallel ПРОГРАММА ::: АРГУМЕНТЫ
Как можно увидеть, аргументы от запускаемой программы отделены тремя символами двоеточия, то есть ::: . Пример запуска пяти экземпляров программы echo у каждого из которого будет свой аргумент (одна цифра):
parallel echo ::: 1 2 3 4 5
Пример вывода:
1 2 3 4 5
Обратите внимание, что в данном и большинстве последующих примеров порядок вывода может быть другим от указанного в примерах, поскольку разные экземпляры запускаемой команды могут закончить работу в разное время.
Также обратите внимание, что разделителем является пробел. Если вам нужно использовать пробел в передаваемом значении, то его нужно экранировать, либо взять передаваемое значение в кавычки:
parallel echo ::: "1 2 3" "4 5 6" "7 8 9"
Будет выведено:
1 2 3 4 5 6 7 8 9
В качестве передаваемых аргументов могут быть файлы, например:
parallel wc ::: example.*
Пример вывода:
1 1 2 example.1 2 2 4 example.2 3 3 6 example.3 4 4 8 example.4 5 5 10 example.5
Если разделитель ::: указать несколько раз, то GNU Parallel сгенерирует все возможные комбинации:
parallel echo ::: S M L ::: Green Red
Вывод:
S Green S Red M Green M Red L Green L Red
GNU Parallel также может считывать значения из stdin (стандартного ввода):
find example.* -print | parallel echo Файл
Вывод:
Файл example.1 Файл example.2 Файл example.3 Файл example.4 Файл example.5
Как можно увидеть, в этом случае не используется последовательность :::, и если уже есть другие аргументы (в данном случае это строка «Файл»), то аргументы из стандартного ввода добавляются в конец строки.
Построение строки команды
Строка запускаемой команды размещается перед ::: . Она может содержать команду и опции для этой команды:
parallel wc -l ::: example.*
Вывод:
1 example.1 2 example.2 3 example.3 4 example.4 5 example.5
Команда может содержать несколько программ. Но помните экранировать символы, которые имеют для оболочки особое значение, например:
parallel echo считаем строки';' wc -l ::: example.*
Вывод:
считаем строки 1 example.1 считаем строки 2 example.2 считаем строки 3 example.3 считаем строки 4 example.4 считаем строки 5 example.5
Опции добавляются к концу команды (после опций), но вы можете разместить их в любом месте, используя строку заполнитель {} :
parallel echo считаем {}';' wc -l {} ::: example.*
Вывод:
считаем example.1 1 example.1 считаем example.2 2 example.2 считаем example.3 3 example.3 считаем example.4 4 example.4 считаем example.5 5 example.5
При использовании нескольких источников ввода, вы можете использовать позиционные (пронумерованные) строки заменители {1} и {2} :
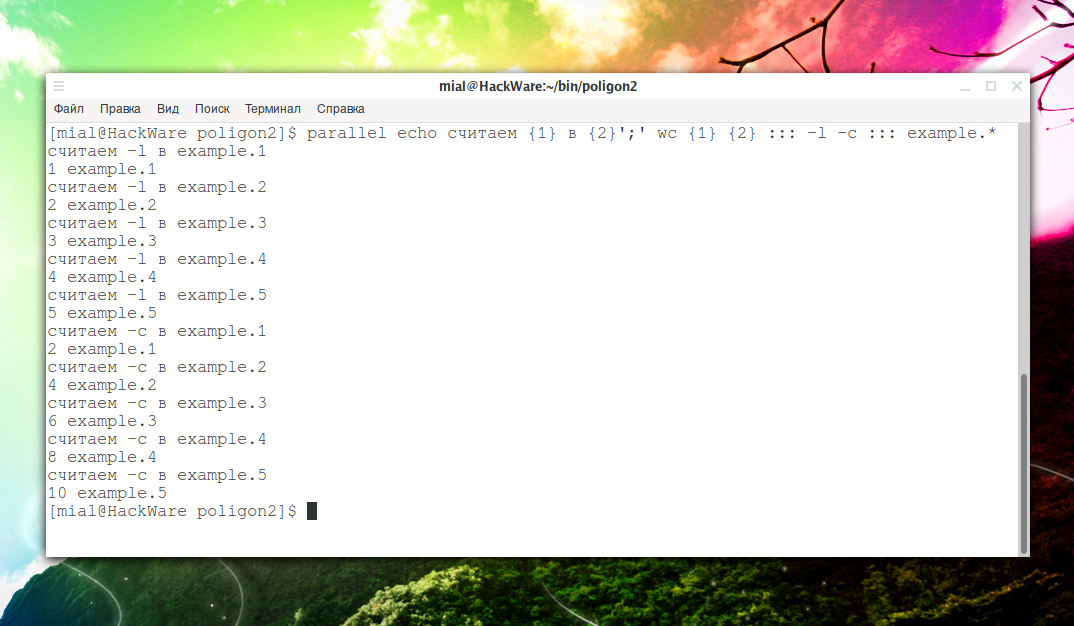
parallel echo считаем {1} в {2}';' wc {1} {2} ::: -l -c ::: example.*
Вывод:
считаем -l в example.1 1 example.1 считаем -l в example.2 2 example.2 считаем -l в example.3 3 example.3 считаем -l в example.4 4 example.4 считаем -l в example.5 5 example.5 считаем -c в example.1 2 example.1 считаем -c в example.2 4 example.2 считаем -c в example.3 6 example.3 считаем -c в example.4 8 example.4 считаем -c в example.5 10 example.5
Проверка сгенерированных команд без их запуска
С опцией --dry-run вы моежте проверить, что именно будет запущено, но фактический запуск сделан не будет:
parallel --dry-run echo считаем {1} в {2}';' wc {1} {2} ::: -l -c ::: example.*
Вывод:
echo считаем -l в example.1; wc -l example.1 echo считаем -l в example.2; wc -l example.2 echo считаем -l в example.3; wc -l example.3 echo считаем -l в example.4; wc -l example.4 echo считаем -l в example.5; wc -l example.5 echo считаем -c в example.1; wc -c example.1 echo считаем -c в example.2; wc -c example.2 echo считаем -c в example.3; wc -c example.3 echo считаем -c в example.4; wc -c example.4 echo считаем -c в example.5; wc -c example.5
Пока вы находитесь в процессе изучения GNU Parallel, то эта опция поможет вам делать отладку вашей команды, также она поможет избежать возможных проблем.
Контроль вывода
Вывод будет напечатан сразу после завершения работы программы. Это означает, что вывод может следовать в отличном от ввода порядке:
parallel sleep {}';' echo {} завершено ::: 5 4 3 2 1
Вывод:
1 завершено 2 завершено 3 завершено 4 завершено 5 завершено
Опцией --keep-order / -k вы можете принудить Parallel печатать в том же порядке что и введённые значения. Команды всё равно будут запущенны параллельно, но вывод результатов более поздних работ будет отложен пока не будут напечатаны результаты более ранних работ:.
parallel --keep-order sleep {}';' echo {} сделано ::: 5 4 3 2 1
Вывод:
5 сделано 4 сделано 3 сделано 2 сделано 1 сделано
Контроль выполнения
Если ваши работы требуют интенсивных вычислений, то весьма вероятно, что вы захотите запускать одну работу на одно ядро системы. GNU Parallel работает так по умолчанию.
Но иногда вам может понадобиться больше запущенных работ, контролировать номера слотов работ вы можете опцией -j / --jobs. Укажите с --jobs количество работ для параллельного запуска. Здесь мы запускаем 2 в параллели:
parallel --jobs 2 sleep {}';' echo {} сделано ::: 5 4 3 1 2
Вывод:
4 сделано 5 сделано 1 сделано 3 сделано 2 сделано
Два слота работ должны запустить 5 работ, которые выполняются 1-5 секунд. В начале одновременно выполняются работы, требующие 5 и 4 секунды, затем одновременно выполняются работы требующие 3 и 1 секунду, последней выполняется работа, требующая 2 секунды.
Если вместо этого запустить параллельно 5 работ, все 5 работ будут запущены в одно и то же время и завершаться в различное время:
parallel --jobs 5 sleep {}';' echo {} сделано ::: 5 4 3 1 2
Вывод:
1 сделано 2 сделано 3 сделано 4 сделано 5 сделано
Вместо указания количества работ для запуска, вы можете передать --jobs 0 и в результате будет запускаться так много параллельных работ, сколько возможно.
Режим Pipe (передача данных по трубе из других программ)
GNU Parallel может также передавать блоки данных командам в stdin (стандартном вводе):
seq 1000000 | parallel --pipe wc
Вывод:
165668 165668 1048571 149796 149796 1048572 149796 149796 1048572 149796 149796 1048572 149796 149796 1048572 149796 149796 1048572 85352 85352 597465
Это может использоваться для обработки больших текстовых файлов. По умолчанию Parallel разбивает по \n (newline) и передаёт блоки примерно по 1 МБ каждой работе.
3. Новые тестовые файлы
Для дальнейших примеров нам понадобятся дополнительные тестовые файлы. Их можно сгенерировать следующим образом:
parallel -k echo ::: A B C > abc-file
parallel -k echo ::: D E F > def-file
perl -e 'printf "A\0B\0C\0"' > abc0-file
perl -e 'printf "A_B_C_"' > abc_-file
perl -e 'printf "f1\tf2\nA\tB\nC\tD\n"' > tsv-file.tsv
perl -e 'for(1..8){print "$_\n"}' > num8
perl -e 'for(1..128){print "$_\n"}' > num128
perl -e 'for(1..30000){print "$_\n"}' > num30000
perl -e 'for(1..1000000){print "$_\n"}' > num1000000
(echo %head1; echo %head2; perl -e 'for(1..10){print "$_\n"}') > num_%header
perl -e 'print "HHHHAAABBBCCC"' > fixedlen
4. Источники ввода
GNU Parallel считывает вводимые данные из источников ввода. Ими могут быть файлы, командная строка stdin (стандартный ввод или труба).
Один источник ввода
Ввод может быть считан из командной строки:
parallel echo ::: A B C
Вывод:
A B C
Источником ввода может быть файл:
parallel -a abc-file echo
Вывод: такой же, как выше.
Источником ввода может быть stdin (стандартный ввод):
cat abc-file | parallel echo
Вывод: такой же, как выше.
Файлом также может быть и FIFO:
mkfifo myfifo cat abc-file > myfifo & parallel -a myfifo echo rm myfifo
Вывод: такой же, как выше.
Или подстановка команды Bash/Zsh/Ksh:
parallel echo :::: <(cat abc-file)
Вывод: такой же, как выше.
Несколько источников ввода
GNU Parallel может принимать в командной строке несколько заданных источников ввода. Тогда Parallel генерирует все комбинации источников ввода:
parallel echo ::: A B C ::: D E F
Вывод:
A D A E A F B D B E B F C D C E C F
Источниками ввода могут быть файлы:
parallel -a abc-file -a def-file echo
Вывод: такой же, как выше.
Stdin (стандартный ввод) может быть одним из источников ввода при использовании - :
cat abc-file | parallel -a - -a def-file echo
Вывод: такой же, как выше.
Вместо использовании опции -a после которой идёт имя файла, этот файл можно указать после :::: (четыре двоеточия) :
cat abc-file | parallel echo :::: - def-file
Вывод: такой же, как выше.
Можно использовать ::: и :::: одновременно:
parallel echo ::: A B C :::: def-file
Вывод: такой же, как выше.
Попарное использование аргументов из различных источников ввода
С опцией --link вы можете задать попарное использование аргументов, пришедших из разных источников ввода (вместо построения всех возможных комбинацией):
parallel --link echo ::: A B C ::: D E F
Вывод:
A D B E C F
Если один из источников ввода слишком короткий, то его значения будут использоваться по кругу:
parallel --link echo ::: A B C D E ::: F G
Вывод:
A F B G C F D G E F
Для более гибкого связывания вы можете использовать :::+ и ::::+ . Они работают как ::: и :::: за исключением того, что они привязывают предыдущий источник ввода к этому источнику ввода.
Следующая команда привяжет ABC к GHI:
parallel echo :::: abc-file :::+ G H I :::: def-file
Вывод:
A G D A G E A G F B H D B H E B H F C I D C I E C I F
Эта команда привяжет GHI к DEF:
parallel echo :::: abc-file ::: G H I ::::+ def-file
Вывод:
A G D A H E A I F B G D B H E B I F C G D C H E C I F
Если один из источников ввода слишком короткий при использовании :::+ или ::::+ , то недостающая для связывания часть будет проигнорирована:
parallel echo ::: A B C D E :::+ F G
Вывод:
A F B G
Изменение разделителя аргументов
Вместо ::: или :::: GNU Parallel может использовать другие разделители. Это обычно полезно если ::: или :::: используется в команде для запуска:
parallel --arg-sep ,, echo ,, A B C :::: def-file
Вывод:
A D A E A F B D B E B F C D C E C F
Изменение разделителя файлового аргумента:
parallel --arg-file-sep // echo ::: A B C // def-file
Вывод: такой же, как предыдущий.
Изменение разделителя записей
GNU Parallel в обычных условиях трактует целую строку как единичную запись: она использует в качестве разделителя записей \n.
С помощью опции -d можно изменить это поведение:
parallel -d _ echo :::: abc_-file
Вывод:
A B C
NUL может быть задан как \0 :
parallel -d '\0' echo :::: abc0-file
Вывод: такой же, как предыдущий.
Сокращением для -d '\0' является -0 (это часто используется для чтения файлов от find … -print0 ):
parallel -0 echo :::: abc0-file
Вывод: такой же, как предыдущий.
Значение конец-файла для источника ввода
GNU Parallel может остановить чтение когда она сталкивается с определённым значение:
parallel -E stop echo ::: A B stop C D
Вывод:
A B
Пропуск пустых строк
Используя опцию --no-run-if-empty вы можете сделать так, что Parallel будет пропускать пустые строки.
(echo 1; echo; echo 2) | parallel --no-run-if-empty echo
Вывод:
1 2
5. Построение строки команды
Parallel по умолчанию запускает команды на основе шаблона в который подставляет значения из источников ввода.
Отсутствие команды означает, что аргументы являются командами
Если команды не даны, то сами аргументы parallel трактует как команды:
parallel ::: ls 'echo foo' pwd
Вывод:
[список файлов в текущей директории] foo [/путь/до/текущей/рабочей/директории]
В качестве команды может быть скрипт, бинарный файл или функция Bash если функция экспортирована с использованием export -f:
# Работает только в Bash
my_func() {
echo в my_func $1
}
export -f my_func
parallel my_func ::: 1 2 3
Вывод:
в my_func 1 в my_func 2 в my_func 3
Если вы используете env_parallel (смотрите далее раздел Трансфер переменных окружения и функций), то вы также можете использовать псевдонимы.
Строки замены (подстановки)
Предопределённые 7 строк замены
GNU Parallel имеет несколько строк замены. Предопределены 7 следующих:
| Строка замены | Значение |
|---|---|
| {} | mydir/mysubdir/myfile.myext |
| {.} | mydir/mysubdir/myfile |
| {/} | myfile.myext |
| {//} | mydir/mysubdir |
| {/.} | myfile |
| {#} | последовательный номер работы |
| {%} | номер слота работы |
Если в команде не используются строки замены, то по умолчанию добавляется {}. Если в команду передаётся строка, то {} означает эту строку, если передаётся имя файла, то означает полный путь до этого файла (как показано в таблице).
parallel echo ::: A/B.C
Вывод:
A/B.C
Дефолтной строкой замены является {}:
parallel echo {} ::: A/B.C
Вывод:
A/B.C
Строка замены {.} удаляет расширение:
parallel echo {.} ::: A/B.C
Вывод:
A/B
Строка замены {/} удаляет путь:
parallel echo {/} ::: A/B.C
Вывод:
B.C
Строка замены {//} оставляет только путь:
parallel echo {//} ::: A/B.C
Вывод:
A
Строка замены {/.} удаляет путь и расширение:
parallel echo {/.} ::: A/B.C
Вывод:
B
Строка замены {#} передаёт номер работы. При запуске каждой работы они получают последовательные номера, которые начинаются на 1 и увеличиваются на 1 для каждой новой работы.
parallel echo {#} ::: A B C
Вывод:
1 2 3
Строка замены {%} передаёт номер слота работы (между 1 и числом запущенных параллельно работ). Каждой работе назначает номер слота. Это номер от 1 до номера параллельно запущенных работ. Он уникален между работающими задачами, но повторно используется как только какая-либо работа завершается.
parallel -j 2 echo {%} ::: A B C
Вывод:
1 2 1
При вставке строка замены помещается в кавычки. Поэтому не нужно беспокоиться об экранировании специальных символов:
echo 'No " needed' | parallel echo {}
Вывод:
No " needed
Если вы не хотите помещать строку в кавычки, то вы можете использовать eval:
echo 'echo foo; echo bar' | parallel echo baz\; eval {}
Вывод:
baz foo bar
Использование других строк замены
Строка замены {} может быть поменяна опцией -I:
parallel -I ,, echo ,, ::: A/B.C
Вывод:
A/B.C
Строка замены {.} может быть поменяна опцией --extensionreplace:
parallel --extensionreplace ,, echo ,, ::: A/B.C
Вывод:
A/B
Строка замены {/} может быть поменяна опцией --basenamereplace:
parallel --basenamereplace ,, echo ,, ::: A/B.C
Вывод:
B.C
Строка замены {//} может быть поменяна опцией --dirnamereplace:
parallel --dirnamereplace ,, echo ,, ::: A/B.C
Вывод:
A
Строка замены {/.} может быть поменяна опцией --basenameextensionreplace / --bner:
parallel --basenameextensionreplace ,, echo ,, ::: A/B.C
Вывод:
B
Строка замены {#} может быть поменяна опцией --seqreplace:
parallel --seqreplace ,, echo ,, ::: A B C
Вывод:
1 2 3
Строка замены {%} может быть поменяна опцией --slotreplace:
parallel -j2 --slotreplace ,, echo ,, ::: A B C
Вывод:
1 2 1
Выражения Perl в качестве строки замены
Если предопределённые строки замены недостаточно гибки, можно вместо них использовать выражения perl. Этот пример удаляет два расширения: foo.tar.gz становится foo
parallel echo '{= s:\.[^.]+$::;s:\.[^.]+$::; =}' ::: foo.tar.gz
Вывод:
foo
Функции для perl выражений в качестве строк замены
В {= =} вы можете получить доступ ко всем внутренним функциям и переменным GNU Parallel. Несколько из них стоит упомянуть.
total_jobs() возвращает общее число работ:
parallel echo Работа {#} из {= '$_=total_jobs()' =} ::: {1..5}
Вывод:
Работа 1 из 5 Работа 2 из 5 Работа 3 из 5 Работа 4 из 5 Работа 5 из 5
slot() возвращает слот работы:
parallel -j2 echo Слот работы {%} = {= '$_=slot()' =} ::: {1..5}
Вывод:
Слот работы 1 = 1 Слот работы 2 = 2 Слот работы 1 = 1 Слот работы 2 = 2 Слот работы 1 = 1
seq() возвращает последовательный номер работы:
parallel echo Работа {#} = {= '$_=seq()' =} ::: a b c
Вывод:
Работа 1 = 1 Работа 2 = 2 Работа 3 = 3
Q(…) помещает строку в кавычки:
parallel echo {} shell quoted is {= '$_=Q($_)' =} ::: '*/!#$'
Вывод:
*/!#$ shell quoted is '*/!#$'
pQ(…) perl помещает строку в кавычки, что полезно если строка замены используется как часть строки Perl и вы не хотите чтобы Perl делал на ней подстановку:
echo '@a' | parallel -q perl -e 'print "{= $_=pQ($_); =}\n"'
Вывод:
@a
skip() пропускает работу:
parallel echo {= 'if($_==3) { skip() }' =} ::: {1..5}
Вывод:
1 2 4 5
@arg содержит переменные источников ввода:
parallel echo {= 'if($arg[1]==$arg[2]) { skip() }' =} ::: {1..3} ::: {1..3}
Вывод:
1 2 1 3 2 1 2 3 3 1 3 2
Если строка {= и =} вызывают проблемы, то она может быть заменена с опцией --parens:
Вывод:
foo
Чтобы задать сокращение строки замены используйте опцию --rpl:
parallel --rpl '.. s:\.[^.]+$::;s:\.[^.]+$::;' echo '..' ::: foo.tar.gz
Вывод: такой же, как и выше.
В Parallel предопределённые 7 строк замены реализованы следующим образом:
| Строка замены | Код |
|---|---|
| {} | |
| {.} | s:\.[^/.]+$:: |
| {/} | s:.*/:: |
| {//} | $Global::use{"File::Basename"} ||= eval "use File::Basename; 1;"; $_ = dirname($_); |
| {/.} | s:.*/::; s:\.[^/.]+$::; |
| {#} | $_=$job->seq() |
| {%} | $_=$job->slot() |
Динамически заменяемые строки
Если в фигурных скобках содержаться парные круглые скобки, то строка замены становится динамической строкой замены, и к строке в круглых скобках можно обратиться как $$1. Если имеется несколько парных круглых скобок, то совпадающие строки будут доступны по $$2, $$3 и так далее.
Вы можете думать об этом как оп ередаче аргументов к строке замены. Здесь мы передаём аргумент .tar.gz строке замены {%string}, которая удаляет string:
parallel --rpl '{%(.+?)} s/$$1$//;' echo {%.tar.gz}.zip ::: foo.tar.gz
Вывод:
foo.zip
Здесь мы передаём два аргумента tar.gz и zip в строку замены {/string1/string2}, которая заменяет string1 на string2:
parallel --rpl '{/(.+?)/(.*?)} s/$$1/$$2/;' echo {/tar.gz/zip} ::: foo.tar.gz
Вывод:
foo.zip
Позиционные строки замены
С несколькими источниками ввода аргумент от индивидуального источника ввода может быть получен по {номеру}:
parallel echo {1} и {2} ::: A B ::: C D
Вывод:
A и C A и D B и C B и D
Позиционная строка замены также может быть модифицирована использованием / , // , /. , и ..
| Строка замены | Значение |
|---|---|
| {3} | mydir/mysubdir/myfile.myext |
| {3.} | mydir/mysubdir/myfile |
| {3/} | myfile.myext |
| {3//} | mydir/mysubdir |
| {3/.} | myfile |
К примеру так:
parallel echo /={1/} //={1//} /.={1/.} .={1.} ::: A/B.C D/E.F
Вывод:
/=B.C //=A /.=B .=A/B /=E.F //=D /.=E .=D/E
Если позиция обозначена отрицательным числом, то она будет обращена к источнику ввода, посчитанному с конца:
parallel echo 1={1} 2={2} 3={3} -1={-1} -2={-2} -3={-3} ::: A B ::: C D ::: E F
Вывод:
1=A 2=C 3=E -1=E -2=C -3=A 1=A 2=C 3=F -1=F -2=C -3=A 1=A 2=D 3=E -1=E -2=D -3=A 1=A 2=D 3=F -1=F -2=D -3=A 1=B 2=C 3=E -1=E -2=C -3=B 1=B 2=C 3=F -1=F -2=C -3=B 1=B 2=D 3=E -1=E -2=D -3=B 1=B 2=D 3=F -1=F -2=D -3=B
Выражения perl как позиционные строки замены
Для использования выражений perl в качестве позиционной строки замены просто поставьте перед выражением perl число и пробел:
parallel echo '{=2 s:\.[^.]+$::;s:\.[^.]+$::; =} {1}' ::: bar ::: foo.tar.gz
Вывод:
foo bar
Если шортхэнд, определённый опцией --rpl, начинается с {, он также может использоваться как позиционная строка замены:
parallel --rpl '{..} s:\.[^.]+$::;s:\.[^.]+$::;' echo {2..} {1} ::: bar ::: foo.tar.gz
Вывод: такой же, как выше.
Ввод из колонок
Столбцы в файле, при использовании опции --colsep, могут быть привязаны к позиционным строкам замены. Здесь колонки разделены ТАБОМ (\t):
parallel --colsep '\t' echo 1={1} 2={2} :::: tsv-file.tsv
Вывод:
1=f1 2=f2 1=A 2=B 1=C 2=D
Строки замены с предопределёнными заголовками
С опцией --header GNU Parallel будет использовать первое значение источника ввода в качестве имени строки замены. Поддерживается только немодифицирующая опция {}:
parallel --header : echo f1={f1} f2={f2} ::: f1 A B ::: f2 C D
Вывод:
f1=A f2=C f1=A f2=D f1=B f2=C f1=B f2=D
Она используется с --colsep для обработки файлов со величинами, разделёнными ТАБОМ:
parallel --header : --colsep '\t' echo f1={f1} f2={f2} :::: tsv-file.tsv
Вывод:
f1=A f2=B f1=C f2=D
Больше предопределённых строк замены с --plus
Опция --plus добавляет строки замены {+/} {+.} {+..} {+…} {..} {…} {/..} {/…} {##}. Идея в том, что {+foo} соответствует противоположности {foo} и {} = {+/} / {/} = {.} . {+.} = {+/} / {/.} . {+.} = {..} . {+..} = {+/} / {/..} . {+..} = {…} . {+…} = {+/} / {/…} . {+…}.
parallel --plus echo {} ::: dir/sub/file.ex1.ex2.ex3
parallel --plus echo {+/}/{/} ::: dir/sub/file.ex1.ex2.ex3
parallel --plus echo {.}.{+.} ::: dir/sub/file.ex1.ex2.ex3
parallel --plus echo {+/}/{/.}.{+.} ::: dir/sub/file.ex1.ex2.ex3
parallel --plus echo {..}.{+..} ::: dir/sub/file.ex1.ex2.ex3
parallel --plus echo {+/}/{/..}.{+..} ::: dir/sub/file.ex1.ex2.ex3
parallel --plus echo {...}.{+...} ::: dir/sub/file.ex1.ex2.ex3
parallel --plus echo {+/}/{/...}.{+...} ::: dir/sub/file.ex1.ex2.ex3
Вывод:
dir/sub/file.ex1.ex2.ex3
{##} это общее число работ:
parallel --plus echo Работа {#} из {##} ::: {1..5}
Вывод:
Работа 1 из 5 Работа 2 из 5 Работа 3 из 5 Работа 4 из 5 Работа 5 из 5
Динамическая строка замены с --plus
--plus также определяет следующие динамические строки замены:
| Строка замены | Значение | Похожее в Bash |
|---|---|---|
| {:-строка} | Если аргумент является пустым, то значением по умолчанию является строка. | ${myvar:-myval} |
| {:число} | Подстрока от числа до конца строки. | ${myvar:2} |
| {:число1:число2} | Подстрока от числа1 до числа2. | ${myvar:2:3} |
| {#строка} | Если аргумент начинается со строки, удалить его. | ${myvar#bc} |
| {%строка} | Если аргумент заканчивается на строку, удалить его. | ${myvar%de} |
| {/строка1/строка2} | Заменить строку1 на строку 2. | ${myvar/def/ghi} |
| {^строка} | Если аргумент начинается на строку, перевести её в верхний регистр. Строка должна быть единичным символом. | ${myvar^a} |
| {^^строка} | Если аргумент содержит строку, перевести её в верхний регистр. Строка должна быть единичным символом. | ${myvar^^a} |
| {,строка} | Если аргумент начинается со строки, перевести его в нижний регистр. Строка должна быть единичным символом. | ${myvar,A} |
| {,,строка} | Если аргумент содержит строку, перевести её в нижний регистр. Строка должна быть единичной буквой. | ${myvar,,A} |
Они вдохновлены аналогичным синтаксисом в Bash:
unset myvar
echo ${myvar:-myval}
parallel --plus echo {:-myval} ::: "$myvar"
myvar=abcAaAdef
echo ${myvar:2}
parallel --plus echo {:2} ::: "$myvar"
echo ${myvar:2:3}
parallel --plus echo {:2:3} ::: "$myvar"
echo ${myvar#bc}
parallel --plus echo {#bc} ::: "$myvar"
echo ${myvar#abc}
parallel --plus echo {#abc} ::: "$myvar"
echo ${myvar%de}
parallel --plus echo {%de} ::: "$myvar"
echo ${myvar%def}
parallel --plus echo {%def} ::: "$myvar"
echo ${myvar/def/ghi}
parallel --plus echo {/def/ghi} ::: "$myvar"
echo ${myvar^a}
parallel --plus echo {^a} ::: "$myvar"
echo ${myvar^^a}
parallel --plus echo {^^a} ::: "$myvar"
myvar=AbcAaAdef
echo ${myvar,A}
parallel --plus echo '{,A}' ::: "$myvar"
echo ${myvar,,A}
parallel --plus echo '{,,A}' ::: "$myvar"
Вывод:
myval myval cAaAdef cAaAdef cAa cAa abcAaAdef abcAaAdef AaAdef AaAdef abcAaAdef abcAaAdef abcAaA abcAaA abcAaAghi abcAaAghi AbcAaAdef AbcAaAdef AbcAAAdef AbcAAAdef abcAaAdef abcAaAdef abcaaadef abcaaadef
Вставка более чем одного аргумента
С опцией --xargs Parallel вставит так много аргументов, сколько это возможно для одной строки:
cat num30000 | parallel --xargs 'echo {} | wc -w'
Вывод:
6310 23690
30000 аргументов распределены на 2 строки команды: 23690 аргументов для первой команды и 6310 для второй.
Максимальная длина одной строки может быть установлена с -s. С максимальной длинной в 30000 символов, 6 команд будут запущены с примерно 5000 аргументами для каждой команды:
cat num30000 | parallel --xargs -s 30000 'echo {} | wc -w'
Вывод:
6218 5628 4997 4997 4997 3163
Для лучшего параллелизма, GNU Parallel может распределять аргументы между всеми параллельными работами когда встречается конец-файла.
Ниже Parallel считывает последний аргумент при генерации второй работы. Когда Parallel считывает последний аргумент, она распределяет все аргументы для второй работы по 4 работам поскольку запрошены 4 параллельных работы.
При использовании -m первая работа будет такой же, как и с опцией --xargs пример с которой показан выше, но вторая работа будет разбита на 4 одинаковых по размеру работы, в результате всего будет 5 работ:
cat num30000 | parallel -j 4 -m 'echo {} | wc -w'
Вывод:
23690 1578 1578 1578 1576
Ещё более наглядно при запуске 4 работ с 10 аргументами. 10 аргументов будут распределены по 4 работам:
parallel --jobs 4 -m echo ::: 1 2 3 4 5 6 7 8 9 10
Вывод:
1 2 3 4 5 6 7 8 9 10
Строка замены может быть частью слова. Опция -m не будет повторять контекст, который соприкасается со строкой замены:
parallel --jobs 4 -m echo до-{}-после ::: A B C D E F G
Вывод:
до-A B-после до-C D-после до-E F-после до-G-после
Для повторения контекста используйте переключатель -X, который в противном случае работает как -m:
parallel --jobs 4 -X echo до-{}-после ::: A B C D E F G
Вывод:
до-A-после до-B-после до-C-после до-D-после до-E-после до-F-после до-G-после
Для ограничения количества аргументов используйте опцию -N:
parallel -N3 echo ::: A B C D E F G H
Вывод:
A B C D E F G H
-N также устанавливает позиционные строки замены:
parallel -N3 echo 1={1} 2={2} 3={3} ::: A B C D E F G H
Вывод:
1=A 2=B 3=C 1=D 2=E 3=F 1=G 2=H 3=
-N0 считывает 1 аргумент, но ничего не вставляет:
parallel -N0 echo foo ::: 1 2 3
Вывод:
foo foo foo
Это полезно для параллельного запуска одной и той же команды много раз.
Помещение строки команды в кавычки
Строки команд, содержащих специальные символы, может понадобиться защитить от интерпретации их оболочкой.
Программа perl печатает "@ARGV\n" в основе работает как echo.
perl -e 'print "@ARGV\n"' A
Вывод:
A
Для запуска её в параллели она требует быть помещённой в кавычки:
parallel perl -e 'print "@ARGV\n"' ::: Это не сработает
Вывод:
[Ничего — она не работает]
Для помещения команды в кавычки, используйте опцию -q:
parallel -q perl -e 'print "@ARGV\n"' ::: Это работает
Вывод:
Это работает
Вы можете поместить в кавычки критическую часть используя \' :
parallel perl -e \''print "@ARGV\n"'\' ::: Это тоже работает
Вывод:
Это тоже работает
GNU Parallel также может \ -quote целые строки. Просто запустите это:
parallel --shellquote Warning: Input is read from the terminal. You either know what you Warning: are doing (in which case: YOU ARE AWESOME!) or you forgot Warning: ::: or :::: or to pipe data into parallel. If so Warning: consider going through the tutorial: man parallel_tutorial Warning: Press CTRL-D to exit.
Затем введите:
perl -e 'print "@ARGV\n"'
и нажмите [CTRL-D]
Вывод:
'perl -e '"'"'print "@ARGV\n"'"'"
Это можно использовать в качестве команды:
parallel 'perl -e '"'"'print "@ARGV\n"'"'" ::: Это также работает
Вывод:
Это также работает
Обрезка пробелов из аргументов
Если вам нужно обрезать конечные пробелы, то используйте опцию --trim:
parallel --trim r echo до-{}-после ::: ' A '
Вывод:
до- A-после
Удаление пробелов с левой стороны:
parallel --trim l echo до-{}-после ::: ' A '
Вывод:
до-A -после
Удаление пробелов с обеих сторон:
parallel --trim lr echo до-{}-после ::: ' A '
Вывод:
до-A-после
Работа в различных оболочках
Это руководство использует в качестве оболочки Bash. GNU Parallel учитывает то, какую оболочку она использует, то есть в zsh вы можете делать:
parallel echo \={} ::: zsh bash ls
Вывод:
/usr/bin/zsh /bin/bash /bin/ls
В csh вы можете делать:
parallel 'set a="{}"; if( { test -d "$a" } ) echo "$a is a dir"' ::: *
Вывод:
[somedir] is a dir
Это также становится полезным если вы используете GNU Parallel в скрипте оболочки: Parallel будет использовать ту же самую оболочку, что и скрипт оболочки.
6. Контроль вывода
По общему правилу GNU Parallel печатает вывод от работы когда она завершена.
Добавление тэга перед выводом
Перед каждой строкой вывода можно добавить значение аргумента:
parallel --tag echo foo-{} ::: A B C
Вывод:
A foo-A B foo-B C foo-C
--tag это сокращение --tagstring {}. Чтобы указать в качестве префикса другую строку, используйте --tagstring:
parallel --tagstring {}-bar echo foo-{} ::: A B C
Вывод:
A-bar foo-A B-bar foo-B C-bar foo-C
Просмотр генерируемых команд без их запуска
Чтобы узнать, какие команды будут запущены, но при этом их не запускать, используйте опцию --dryrun:
parallel --dryrun echo {} ::: A B C
Вывод:
echo A echo B echo C
Чтобы вывода команд перед их запуском используйте флаг --verbose:
parallel --verbose echo {} ::: A B C
Вывод:
echo A echo B A echo C B C
Но эта информация соответствует действительности не во всех случаях — при использовании --nice, --pipepart, или когда работа запускается на удалённой машине, то команда оборачивается в дополнительный код. Подробности будут рассмотрены в конце раздела Удалённое выполнение.
Принудительный порядок в соответствии с вводом
Эта функция:
half_line_print() {
printf "%s-начало\n%s" $1 $1
sleep $1
printf "%s\n" -середина
echo $1-конец
}
export -f half_line_print
принимает в качестве аргумента число (#). Она печатает полную строку ‘#-начало’ за которой следует половина строки ‘#’. Затем она засыпает на # секунд, далее печатает ‘-середина’ за которой следует ‘#-конец’.
Чтобы сделать так, чтобы вывод разных команд не перемешивался и следовал один за другим в таком же порядке как и аргументы, используйте флаг --keep-order / -k:
parallel -j2 -k half_line_print ::: 4 2 1
Вывод:
4-начало 4-середина 4-конец 2-начало 2-середина 2-конец 1-начало 1-середина 1-конец
Вывод до завершения работы
GNU Parallel откладывает вывод пока команда не завершиться:
parallel -j2 half_line_print ::: 4 2 1
Вывод:
2-начало 2-середина 2-конец 1-начало 1-середина 1-конец 4-начало 4-середина 4-конец
Это из-за того, что опция --group включена по умолчанию. Для немедленного получения вывода, используйте опцию --ungroup / -u:
parallel -j2 --ungroup half_line_print ::: 4 2 1
Вывод:
4-начало 42-начало 2-середина 2-конец 1-начало 1-середина 1-конец -середина 4-конец
--ungroup является быстрой, но отключает --tag и может быть причиной разрыва строк и перемешивания вывода от разных работ даже на одной строке. Это произошло на второй строке последнего примере, где перемешены строки «42-начало» и «-середина».
Чтобы избежать этого, используйте опцию --linebuffer, с которой программа будет выводить только полные строки:
parallel -j2 --linebuffer half_line_print ::: 4 2 1
Вывод:
4-начало 2-начало 2-середина 2-конец 1-начало 1-середина 1-конец 4-середина 4-конец
С --keep-order --line-buffer GNU Parallel будет последовательно выводить строки от первой работы, пока она не завершиться, затем GNU Parallel будет последовательно выводить строки от второй работы пока она работает. Она будет помещать в буфер целые строки, но вывод от разных работ не будет смешиваться.
Сравните:
parallel -j4 'echo {}-a;sleep {};echo {}-b' ::: 1 3 2 4
Вывод:
1-a 1-b 2-a 2-b 3-a 3-b 4-a 4-b
С:
parallel -j4 --line-buffer 'echo {}-a;sleep {};echo {}-b' ::: 1 3 2 4
Вывод:
1-a 3-a 2-a 4-a 1-b 2-b 3-b 4-b
И с:
parallel -j4 -k --line-buffer 'echo {}-a;sleep {};echo {}-b' ::: 1 3 2 4
Вывод:
1-a 1-b 3-a 3-b 2-a 2-b 4-a 4-b
Буферизация на диск
Parallel использует в качестве буфера временные файлы. Если у программы больше вывода, чем свободного места на диске, то при использовании --group или --line-buffer --keep-order диск будет заполнен. Это не происходит при использовании --line-buffer без --line-buffer (которая сохраняет в буфер одну строку в оперативной памяти) и --ungroup (которая вовсе не использует буфер).
Сохранение вывода в файлы
GNU Parallel может сохранять вывод для каждой работы в файлы:
parallel --files echo ::: A B C
Вывод будет примерно таким:
/tmp/par3QREJ.par /tmp/parynX_T.par /tmp/pariNYyN.par
По умолчанию Parallel кэширует вывод в файлы в /tmp. Это можно изменить установкой $TMPDIR или --tmpdir:
parallel --tmpdir /var/tmp --files echo ::: A B C
Вывод будет примерно таким:
/var/tmp/parovWfC.par /var/tmp/parzoKjh.par /var/tmp/parTxqLd.par
Или:
TMPDIR=/var/tmp parallel --files echo ::: A B C
Вывод: такой же, как предыдущий.
С использованием опции --results файлы могут быть сохранены структурировано:
parallel --results outdir echo ::: A B C
Вывод:
A B C
Также генерируются файлы, содержащие стандартный вывод (stdout), стандартный вывод ошибок (stderr) и последовательный номер (seq):
outdir/1/A/seq outdir/1/A/stderr outdir/1/A/stout outdir/1/B/seq outdir/1/B/stderr outdir/1/B/stdout outdir/1/C/seq outdir/1/C/stderr outdir/1/C/stdout
Опция --header примет первое значение в качестве имени и использует его в структуре директории. Это полезно при использовании нескольких источников ввода:
parallel --header : --results outdir echo ::: f1 A B ::: f2 C D
Сгенерированные файлы:
outdir/f1/A/f2/C/seq outdir/f1/A/f2/C/stderr outdir/f1/A/f2/C/stdout outdir/f1/A/f2/D/seq outdir/f1/A/f2/D/stderr outdir/f1/A/f2/D/stdout outdir/f1/B/f2/C/seq outdir/f1/B/f2/C/stderr outdir/f1/B/f2/C/stdout outdir/f1/B/f2/D/seq outdir/f1/B/f2/D/stderr outdir/f1/B/f2/D/stdout
Директории называются по переменным и их значениям.
Если аргумент для --results содержит строку замены, stdout будет сохранён под этим именем:
parallel --results my{1}-{2}.out echo ::: A B ::: C D
Сгенерированные файлы:
myA-C.out myA-D.out myB-C.out myB-D.out
Если аргумент для --results содержит строку замены и оканчивается на / , вывод будет сохранён в директорию с этим именем:
parallel --results my{1}-{2}-dir/ echo ::: A B ::: C D
Сгенерированные файлы:
myA-C-dir/stderr myA-C-dir/seq myA-C-dir/stdout myA-D-dir/stderr myA-D-dir/seq myA-D-dir/stdout myB-C-dir/stderr myB-C-dir/seq myB-C-dir/stdout myB-D-dir/stderr myB-D-dir/seq myB-D-dir/stdout
Сохранение в CSV/TSV
Многие программы поддерживают файлы Значений разделённых запятой (Comma Separated Values)/Значений, разделённых ТАБОМ (Tab Separated Values). И Parallel не является исключением. Если аргумент для --results оканчивается на .csv или .tsv, то в качестве вывода будет файл CSV/TSV.
parallel --results my.csv echo ::: A B ::: C D
Содержимое my.csv:
Seq,Host,Starttime,JobRuntime,Send,Receive,Exitval,Signal,Command,V1,V2,Stdout,Stderr 1,:,1561779071.202,0.002,0,4,0,0,"echo A C",A,C,"A C ", 2,:,1561779071.203,0.003,0,4,0,0,"echo A D",A,D,"A D ", 3,:,1561779071.204,0.003,0,4,0,0,"echo B C",B,C,"B C ", 4,:,1561779071.206,0.003,0,4,0,0,"echo B D",B,D,"B D ",
Это быстрее, чем использование CSV в качестве SQL базы данных.
Сохранение в SQL базу данных
Parallel может сохранять в SQL базу. Укажите GNU Parallel на таблицу и она поместит туда лог работы вместе с переменными и выводом — каждый в своём собственном столбце.
CSV как SQL база
Самое простое это использование CSV в качестве таблицы хранилища:
parallel --sqlandworker csv:////%2Ftmp%2Flog.csv seq ::: 10 ::: 12 13 14 cat /tmp/log.csv
Обратите внимание, что '/' в пути должна быть записана как %2F.
Вывод будет примерно таким:
Seq,Host,Starttime,JobRuntime,Send,Receive,Exitval,_Signal,Command,V1,V2,Stdout,Stderr 1,HackWare,1561783972.501,0.005,0,9,0,0,"seq 10 12",10,12,"10 11 12 ", 2,HackWare,1561783972.504,0.008,0,12,0,0,"seq 10 13",10,13,"10 11 12 13 ", 3,HackWare,1561783972.51,0.006,0,15,0,0,"seq 10 14",10,14,"10 11 12 13 14 ",
Первая колонка хорошо известна по опции --joblog. V1 и V2 это данные из источников ввода. Stdout и Stderr это, соответственно, стандартный вывод и стандартный вывод ошибок.
Программы, которые умеют работать с CSV (такие как LibreOffice или команда read.csv из R) прочитают этот формат корректно — даже если поля содержат переносы строк как в примере выше.
Если вывод велик вы можете захотеть поместить его в файлы используя --results. В этом случае CSV файл будет содержать имена файлов:
parallel --results outdir --sqlandworker csv:////%2Ftmp%2Flog2.csv seq ::: 10 ::: 12 13 14 cat /tmp/log2.csv
Вывод примерно такой:
Seq,Host,Starttime,JobRuntime,Send,Receive,Exitval,_Signal,Command,V1,V2,Stdout,Stderr 1,HackWare,1561786100.346,0.006,0,9,0,0,"seq 10 12",10,12,outdir/1/10/2/12/stdout,outdir/1/10/2/12/stderr 2,HackWare,1561786100.35,0.009,0,12,0,0,"seq 10 13",10,13,outdir/1/10/2/13/stdout,outdir/1/10/2/13/stderr 3,HackWare,1561786100.356,0.006,0,15,0,0,"seq 10 14",10,14,outdir/1/10/2/14/stdout,outdir/1/10/2/14/stderr
DBURL в качестве таблицы
Файл CSV это пример DBURL.
GNU Parallel использует DBURL для адресации к таблицам. DBURL имеет следующий формат:
вендор://[[пользователь][:пароль]@][хост][:порт]/[база данных[/таблица]
Примеры:
mysql://scott:tiger@my.example.com/mydatabase/mytable postgresql://scott:tiger@pg.example.com/mydatabase/mytable sqlite3:///%2Ftmp%2Fmydatabase/mytable csv:////%2Ftmp%2Flog.csv
Для указания на /tmp/mydatabase с sqlite или csv вам нужно кодировать / на %2F.
Запуск работы используя sqlite на mytable в /tmp/mydatabase:
DBURL=sqlite3:///%2Ftmp%2Fmydatabase DBURLTABLE=$DBURL/mytable parallel --sqlandworker $DBURLTABLE echo ::: foo bar ::: baz quux
Для просмотра результатов:
sql $DBURL 'SELECT * FROM mytable ORDER BY Seq;'
Вывод будет примерно таким:
Seq|Host|Starttime|JobRuntime|Send|Receive|Exitval|_Signal|Command|V1|V2|Stdout|Stderr 1|HackWare|1561786308.204|0.002|0|8|0|0|echo foo baz|foo|baz|foo baz | 2|HackWare|1561786308.206|0.001|0|9|0|0|echo foo quux|foo|quux|foo quux | 3|HackWare|1561786308.208|0.002|0|8|0|0|echo bar baz|bar|baz|bar baz | 4|HackWare|1561786308.209|0.002|0|9|0|0|echo bar quux|bar|quux|bar quux |
Использование нескольких воркеров
Использование SQL базы в качестве хранилища требует дополнительных затрат порядка 1 секунды на задание. Одна из ситуаций, где это имеет смысл, когда вы должны использовать несколько воркеров.
Вы можете иметь один главный компьютер, который отправляет задания в SQL базу (но который не выполняет никакой работы):
parallel --sqlmaster $DBURLTABLE echo ::: foo bar ::: baz quux
На машине-воркере (где выполняется задача) вы можете запустить в точности такую же команду, за исключением того, что вы заменяете --sqlmaster на --sqlworker.
parallel --sqlworker $DBURLTABLE echo ::: foo bar ::: baz quux
Для запуска мастера и воркера на одной и той же машине используйте --sqlandworker как это показано ранее.
Экземпляр запущенный с --sqlmaster выйдет как только работы помещены в базу данных (если не указана опция --wait). Эта опция сделает так, что машина с --wait перед выходом будет ждать завершение всех работ.
Вы можете добавить больше работ в существующую таблицу поставив + перед DBURLTABLE:
parallel --sqlmaster +$DBURLTABLE echo ::: foo2 bar2 ::: baz2 quux2
Сохранение вывода в переменные оболочки
GNU Parset установит переменные оболочки для вывода GNU Parallel. GNU Parset имеет одно важное ограничение: он не может быть частью трубы. В частности, это означает, что он ничего не может прочитать из стандартного ввода (stdin) или конвейерного (по трубе) вывода в другую программу.
GNU Parset — это функция оболочки. Для её активации:
env_parallel --install
После этого будет запущена новая оболочка.
Parset поддерживается для bash, dash, ash, sh, ksh и zsh .
Для использования parset поместите переменные назначения перед обычными опциями и командой GNU Parallel:
parset myvar1,myvar2 -j2 echo ::: a b echo $myvar1 echo $myvar2
Вывод:
a b
Если вы передали только одну переменную, она будет трактоваться как массив:
parset myarray seq {} 5 ::: 1 2 3
echo "${myarray[1]}"
Вывод:
2 3 4 5
Командами для запуска может быть массив:
cmd=("echo '<<Joe \"double space\"
parset data -j2 ::: "${cmd[@]}"
echo "${data[0]}"
echo "${data[1]}"
cartoon>>'" "pwd")
Вывод:
<<Joe "double [текущая директория] space" cartoon>>
Чтение из трубы (конвейерный ввод)
GNU Parset не может читать из трубы поскольку сама программа запускается в под-оболочке и, следовательно, вывод не будет виден в запустившей оболочке. Для обхода этой проблемы имеется несколько вариантов.
Использование временного файла
Вместо чтения непосредственно из трубы, сохраните вывод в файл и затем пусть parset прочитает его:
seq 3 > parallel_input parset res1,res2,res3 echo :::: parallel_input echo "$res1" echo "$res2" echo "$res3" rm parallel_input
Использование подстановку процесса
Если ваша оболочка поддерживает подстановку процесса (Bash, Zsh и Ksh это могут), тогда вы можете использовать следующее:
parset res echo :::: <(seq 100)
echo "${res[1]}"
echo "${res[99]}"
Используйте FIFO
Если количество данных великов или вам нужно, чтобы GNU Parset начал читать до того, как сгенерирован весь вывод, то вариантом может быть использование FIFO.
mkfifo input_fifo seq 3 > input_fifo & parset res1,res2,res3 echo :::: input_fifo echo "$res1" echo "$res2" echo "$res3" rm input_fifo
env_parset
env_parset будет делать то же самое, что и parset, но используя env_parallel (смотрите далее Передача переменных окружения и функций) вместо parallel, поскольку вам понадобиться доступ к псевдонимам, неэкспортируемым функциям и неэкспортируемым переменным.
7. Контроль выполнения
По умолчанию GNU Parallel запускает параллельно одну работу на каждое ядро центрального процессора и завершается когда все работы выполнены.
Количество одновременных работ
Количество параллельных работ указывается с опцией --jobs / -j (-N0 считывает единичный аргумент, но ничего не вставляет — поэтому он запускает параллельно много раз sleep 1):
/usr/bin/time parallel -N0 -j64 sleep 1 :::: num128
С 64 работами в параллели, 128 sleep потребуют 2-8 секунды для работы — зависит от того, насколько быстрая ваша машина.
По умолчанию значение опции --jobs равно количеству ядер CPU. Поэтому это:
/usr/bin/time parallel -N0 sleep 1 :::: num128
должно занять в два раза больше времени на запуск 2 работ на каждое ядро центрального процессора:
/usr/bin/time parallel -N0 --jobs 200% sleep 1 :::: num128
--jobs 0 запустит так много одновременных работ, насколько это возможно:
/usr/bin/time parallel -N0 --jobs 0 sleep 1 :::: num128
это займёт 1-7 секунд в зависимости от того, насколько быстрая у вас машина.
--jobs может читать из файла и перечитывать когда работа завершена:
echo 50% > my_jobs /usr/bin/time parallel -N0 --jobs my_jobs sleep 1 :::: num128 & sleep 1 echo 0 > my_jobs wait
GNU Parallel при запуске считает my_jobs. Он содержит значение 50% поэтому Parallel будет делать вычисления на 50% числа ядер и запустит это количество работ в параллели.
Из-за символа & программа Parallel будет запущена в фоне.
После одной секунды в my_jobs сохраняется 0. Когда работа закончена, Parallel повторно считывает my_jobs, и затем Parallel запускает так много работ, как возможно.
Указанные проценты применяются к количеству ядер центрального процессора, но с помощью соответствующей опции можно сделать так, что Parallel за основу возьмёт количество центральных процессоров:
parallel --use-cpus-instead-of-cores -N0 sleep 1 :::: num8
Перемешивание последовательности работ
Если у вас много работ (к примеру много комбинаций источников ввода), то может быть полезным перемешать работы, чтобы они выполнялись в случайном порядке. Для этого используйте опцию --shuf:
parallel --shuf echo ::: 1 2 3 ::: a b c ::: A B C
Вывод: все комбинации, но при каждом запуске порядок будет разный.
Интерактивность
Parallel может спрашивать пользователя, должна ли команда быть запущена, для этого используется опция --interactive:
parallel --interactive echo ::: 1 2 3
Вывод:
echo 1 ?...y echo 2 ?...n 1 echo 3 ?...y 3
Parallel может использоваться для помещения аргументов в командную строку для интерактивных команд, таких как emacs для редактирования одно файла за раз:
parallel --tty emacs ::: file1 file2 file3
Или передачи нескольких аргументов за один проход в несколько открытых файлов:
parallel -X --tty vi ::: file1 file2 file3
Терминал для каждой работы
При использовании --tmux программа Parallel может открыть терминал для каждой запускаемой работы:
seq 10 20 | parallel --tmux 'echo start {}; sleep {}; echo done {}'
Это скажет вам запустить что-то вроде:
tmux -S /tmp/tmsrPrO0 attach
Используя комбинации клавиш tmux (CTRL-b n или CTRL-b p) вы можете переключаться по кругу между окнами запущенных работ. Когда работа завершается, она ставится на паузу на 10 секунд перед закрытием окна.
Чтобы Parallel оставляла открытым окно каждой работы в своей собственной панели, используйте --tmuxpane. --fg немедленно подключится к tmux:
parallel --tmuxpane --fg 'echo start {}; sleep {}; echo done {}' ::: 10 11 12 13 14 15 16 17
Тайминги
Некоторые работы при запуске интенсивно читают или пишут на диск. Чтобы избежать проблем из-за этого, Parallel может задерживать запуск новых работ. Опция --delay X сделает так, что будет по крайней мере X секунд между каждым стартом:
parallel --delay 2.5 echo Запуск {}\;date ::: 1 2 3
Вывод:
Запуск 1 Чт июн 27 18:28:08 MSK 2019 Запуск 2 Чт июн 27 18:28:11 MSK 2019 Запуск 3 Чт июн 27 18:28:13 MSK 2019
Если работы занимают больше времени чем должны при нормальной работе, то они могут быть остановлены по таймауту опцией --timeout. Точность --timeout составляет 2 секунды. --timeout 100000 можно записать как --timeout 1d3.5h16.6m4s.
parallel --timeout 4.1 sleep {}\; echo {} ::: 2 4 6 8
Вывод:
2 4 parallel: Warning: This job was killed because it timed out: parallel: Warning: sleep 6; echo 6 parallel: Warning: This job was killed because it timed out: parallel: Warning: sleep 8; echo 8
GNU Parallel может рассчитывать медианное время выполнение для работ и закрывать те, которые потребляют более 200% медианного времени выполнения:
parallel --timeout 200% sleep {}\; echo {} ::: 2.1 2.2 3 7 2.3
Вывод:
2.1 2.2 2.3 3 parallel: Warning: This job was killed because it timed out: parallel: Warning: sleep 7; echo 7
Это полезно если с некоторыми работами что-то пошло не так и им нужно намного больше времени чем остальным работам.
Информация о прогрессе
На основе времени выполнения завершённых работ Parallel может прикинуть общее время выполнения:
parallel --eta sleep ::: 1 3 2 2 1 3 3 2 1
Вывод:
Computers / CPU cores / Max jobs to run 1:local / 12 / 9 Computer:jobs running/jobs completed/%of started jobs/Average seconds to complete ETA: 0s Left: 0 AVG: 0.22s local:0/9/100%/0.3s
Parallel с опцией --progress покажет информацию о прогрессе:
parallel --progress sleep ::: 1 3 2 2 1 3 3 2 1
Вывод:
Computers / CPU cores / Max jobs to run 1:local / 12 / 9 Computer:jobs running/jobs completed/%of started jobs/Average seconds to complete local:0/9/100%/0.3s
Опция --bar используется для вывода полосы прогресса:
parallel --bar sleep ::: 1 3 2 2 1 3 3 2 1
И графическая полоса програссе может быть показана с --bar и zenity:
seq 1000 | parallel -j10 --bar '(echo -n {};sleep 0.1)' 2> >(zenity --progress --auto-kill --auto-close)
Файл журнала
Для закончивших выполнение работ с помощью опции --joblog можно сгенерировать лог:
parallel --joblog /tmp/log exit ::: 1 2 3 0 cat /tmp/log
Вывод:
Seq Host Starttime JobRuntime Send Receive Exitval Signal Command 1 : 1561700019.328 0.000 0 0 1 0 exit 1 2 : 1561700019.329 0.003 0 0 2 0 exit 2 3 : 1561700019.331 0.001 0 0 3 0 exit 3 4 : 1561700019.332 0.002 0 0 0 0 exit 0
Журнал содержит последовательность работ, хост, на котором они были запущены, время старта и время работы, как много данных было передано, статус выхода, сигнал, который убил работу и, наконец, команду, которая была запущена.
Возобновление работ
При запуске с --joblog, Parallel может быть остановлена до окончания всех работ и затем запущена с того же самого места. Важно, чтобы ввод завершённых работ был неизменным.
parallel --joblog /tmp/log exit ::: 1 2 3 0 cat /tmp/log
Вывод:
Seq Host Starttime JobRuntime Send Receive Exitval Signal Command 1 : 1561702292.461 0.000 0 0 1 0 exit 1 2 : 1561702292.462 0.003 0 0 2 0 exit 2 3 : 1561702292.464 0.002 0 0 3 0 exit 3 4 : 1561702292.465 0.002 0 0 0 0 exit 0
parallel --resume --joblog /tmp/log exit ::: 1 2 3 0 0 0 cat /tmp/log
Вывод:
1 : 1561702292.461 0.000 0 0 1 0 exit 1 2 : 1561702292.462 0.003 0 0 2 0 exit 2 3 : 1561702292.464 0.002 0 0 3 0 exit 3 4 : 1561702292.465 0.002 0 0 0 0 exit 0 5 : 1561702305.992 0.000 0 0 0 0 exit 0 6 : 1561702305.993 0.001 0 0 0 0 exit 0
Обратите внимание, что время запуск последних 2 работ явно отличается от первого запуска.
С опцией --resume-failed GNU Parallel перезапустит работы, которые завершились неудачей:
parallel --resume-failed --joblog /tmp/log exit ::: 1 2 3 0 0 0 cat /tmp/log
Вывод:
Seq Host Starttime JobRuntime Send Receive Exitval Signal Command 1 : 1561702292.461 0.000 0 0 1 0 exit 1 2 : 1561702292.462 0.003 0 0 2 0 exit 2 3 : 1561702292.464 0.002 0 0 3 0 exit 3 4 : 1561702292.465 0.002 0 0 0 0 exit 0 5 : 1561702305.992 0.000 0 0 0 0 exit 0 6 : 1561702305.993 0.001 0 0 0 0 exit 0 1 : 1561703134.226 0.003 0 0 1 0 exit 1 2 : 1561703134.228 0.002 0 0 2 0 exit 2 3 : 1561703134.229 0.001 0 0 3 0 exit 3
Обратите внимание, как были повторены seq 1 2 3 поскольку они имели значение статуса выхода отличное от 0.
Опция --retry-failed делает почти то же самое, что и --resume-failed. Опция --resume-failed считывает команды из командной строки (и игнорирует команды от --joblog), --retry-failed игнорирует командную строку и возвращает команды, упомянутые в --joblog.
parallel --retry-failed --joblog /tmp/log cat /tmp/log
Вывод:
Seq Host Starttime JobRuntime Send Receive Exitval Signal Command 1 : 1561702292.461 0.000 0 0 1 0 exit 1 2 : 1561702292.462 0.003 0 0 2 0 exit 2 3 : 1561702292.464 0.002 0 0 3 0 exit 3 4 : 1561702292.465 0.002 0 0 0 0 exit 0 5 : 1561702305.992 0.000 0 0 0 0 exit 0 6 : 1561702305.993 0.001 0 0 0 0 exit 0 1 : 1561703134.226 0.003 0 0 1 0 exit 1 2 : 1561703134.228 0.002 0 0 2 0 exit 2 3 : 1561703134.229 0.001 0 0 3 0 exit 3 1 : 1561703223.842 0.000 0 0 1 0 exit 1 2 : 1561703223.843 0.002 0 0 2 0 exit 2 3 : 1561703223.845 0.001 0 0 3 0 exit 3
Прекращение работы
Безусловное прекращение работы
По умолчанию перед своим выходом Parallel ожидает все работы когда они завершаться.
Если вы отправили в Parallel сигнал TERM, то Parallel прекратит запускать новые работы и будет ждать ожидания уже запущенных работ. Если вы вновь отправили в Parallel сигнал TERM, то Parallel убьёт все запущенные работы и отключится.
Остановка в зависимости от статуса работы
Для определённых работ не нужды продолжать, если одна из работ завершилась неудачей и имет код выхода отличный от 0. GNU Parallel прекратит запуск новых работ с опцией --halt soon,fail=1, например:
parallel -j2 --halt soon,fail=1 echo {}\; exit {} ::: 0 0 1 2 3
Вывод:
0 0 1 parallel: This job failed: echo 1; exit 1 parallel: Starting no more jobs. Waiting for 1 jobs to finish. 2 parallel: This job failed: echo 2; exit 2
Если значение --halt указано в процентах, то этот процент работ должен завершиться неудачей перед тем, как GNU Parallel остановит запуск новых работ:
parallel -j2 --halt soon,fail=20% echo {}\; exit {} ::: 0 1 2 3 4 5 6 7 8 9
Вывод:
0 1 parallel: This job failed: echo 1; exit 1 2 parallel: This job failed: echo 2; exit 2 parallel: Starting no more jobs. Waiting for 1 jobs to finish. 3 parallel: This job failed: echo 3; exit 3
Если вместо неудачных запусков вы ищите успешные. Следующий пример завершиться как только появится первая удачно завершившаяся работа.
parallel -j2 --halt now,success=1 echo {}\; exit {} ::: 1 2 3 0 4 5 6
Вывод:
1 2 3 0 parallel: This job succeeded: echo 0; exit 0
Если вас не волнует значение выхода, но вы хотите просто 3 завершённых работы, вы можете использовать опцию done=3:
parallel -j2 --halt now,done=3 sleep {}\;echo {}\; exit {} ::: 1 2 3 0 4 5 6
Вывод:
1 parallel: This job finished: sleep 1;echo 1; exit 1 2 parallel: This job finished: sleep 2;echo 2; exit 2 0 parallel: This job finished: sleep 0;echo 0; exit 0
Перезапуск неудачных команд
GNU Parallel может повторно запустить команды при использовании опции --retries. Это полезно если команда время от времени неудачно завершается по неизвестным причинам.
parallel -k --retries 3 'echo попытка {} >>/tmp/runs; echo завершено {}; exit {}' ::: 1 2 0
Вывод:
завершено 1 завершено 2 завершено 0
cat /tmp/runs
Вывод:
попытка 1 попытка 2 попытка 1 попытка 0 попытка 2 попытка 1 попытка 2
Обратите внимание, что работа 1 и 2 были запущены 3 раза, но 0 не была запущена вновь, поскольку у неё код статуса выхода равен 0.
При использовании с удалённым выполнением (смотрите далее), то если это возможно, работа будет запущена на другом сервере.
Сигналы терминации
Используя опцию --termseq вы можете контролировать, какие сигналы отправляются, когда завершаются дочерние процессы. По умолчанию дочерние процессы завершаются отправкой им SIGTERM, ожидаем 200 ms, затем другим SIGTERM, ожиданием 100 ms, затем другим SIGTERM, ожиданием 50 ms, затем SIGKILL, и конечным ожиданием 25 ms перед прекращением попыток. Это выглядит примерно так:
show_signals() {
perl -e 'for(keys %SIG) {
$SIG{$_} = eval "sub { print \"Got $_\\n\"; }";
}
while(1){sleep 1}'
}
export -f show_signals
echo | parallel --termseq TERM,200,TERM,100,TERM,50,KILL,25 -u --timeout 1 show_signals
Вывод:
Got TERM Got TERM Got TERM
Или просто:
echo | parallel -u --timeout 1 show_signals
Вывод: такой же, как и предыдущий.
Вы можете заменить сигналы на SIGINT, SIGTERM, SIGKILL:
echo | parallel --termseq INT,200,TERM,100,KILL,25 -u --timeout 1 show_signals
Вывод:
Got INT Got TERM
SIGKILL не показан, поскольку он не может быть перехвачен, но дочерний процесс всё равно завершается.
Ограничение ресурсов
Parallel может запускать работы со означением nice (что-то вроде приоритета процесса при потреблении ресурсов центрального процессора). Это работает как локально, так и удалённо.
parallel --nice 17 echo это запущено с nice -n ::: 17
Вывод:
это запущено с nice -n 17
Чтобы избежать перегрузки системы, Parallel перед запуском ещё следующей работы может свериться с системными ресурсами:
parallel --load 100% echo загрузка менее чем {} работа на CPU ::: 1
Вывод:
[когда загрузка менее чем число CPU ядер] загрузка менее чем 1 работа на CPU
Parallel также может проверить, использует ли система раздел подкачки.
parallel --noswap echo система не использует раздел подкачки ::: сейчас
Вывод:
[когда система не использует раздел подкачки] система не использует раздел подкачки сейчас
Некоторым работам требуется много оперативной памяти и они должны быть запущены только если достаточно свободной памяти. При использовании опции --memfree Parallel может проверить, достаточно ли свободной памяти. Дополнительно Parallel убьёт самую молодую работу, если количество свободной памяти стало менее 50% размера. Убитая работа будет возвращена в очередь и если указана опция --retries, то будет сделана попытка запустить её вновь.
parallel --memfree 1G --retries 5 echo Более чем 1 GB являются ::: свободными
Создание своих собственных ограничений
С опцией --limit вы можете создавать свои собственные ограничения наподобие --memfree и --load. Вам просто нужно сделать программу, которая возврарщает:
| Код статуса выхода | Значение |
|---|---|
| 0 | Ниже лимита. Запуск новой работы. |
| 1 | Выше лимита. Не запускаем работу. |
| 2 | Сильно больше лимита. Убиваем самую молодую работу. |
Имеется 3 предопределённых команды:
| Команда | Значение |
|---|---|
| io n | Лимит для I/O. Количество дискового I/O будет рассчитано как значение в диапазоне 0-100, где 0 означает отсутствие I/O, а 100 означает по крайне мере один диск используется интенсивно на 100%. n устанавливает лимит когда io должен возвращать 1. |
| mem n | Аналогично --memfree |
| load n | Аналогично --load |
Примеры:
parallel --limit "io 10" echo ::: менее чем 10% дискового I/O parallel --limit "mem 10g" echo ::: более чем 10G свободно parallel --limit "load 3" echo ::: менее чем 3 procs запущено
8. Удалённое выполнение
9. Режим Pipe (передача данных по трубе)
10. Прочие функции
11. Примеры
Связанные статьи:
- Какие есть полезные инструменты с интерфейсом командной строки для системных администраторов Linux (52.7%)
- 15 полезных практических примеров команды locate в Linux (52.7%)
- Подстановочные символы, раскрытие, использование кавычек и экранирование символов в Bash (42.6%)
- Cloud Commander – веб файловый менеджер для управления файлами и программами Linux через браузер (39.9%)
- Как отсортировать в алфавитном порядке в Writer (LibreOffice) (39.9%)
- Инструкция по использованию команды file (RANDOM - 10.1%)