Операторы перенаправления вывода в Bash: что означает <<, <<<, < <(КОМАНДА), 2>&1 и другие
Рассмотрим операторы перенаправления вывода Bash и похожие по функции операторы и конструкции. Я собрал следующий список, если что-то пропустил, то пишите в комментариях:
- |
- >
- > /dev/null
- >>
- 2>
- 2>&1
- &>
- &>>
- <
- <<
- <<<
- Почему << (here document) и <<< (here string) нельзя использовать с переменными
- В чём различие << (here document) и <<< (here string)
- <(КОМАНДА)
- >(КОМАНДА)
- < <(КОМАНДА АРГУМЕНТЫ)
- 2> >(КОМАНДА) > /dev/null
- cat > ФАЙЛ <<_EOF_
- cat >> ФАЙЛ <<_EOF_
- cat <<_EOF_ > ФАЙЛ
- cat <<_EOF_ >> ФАЙЛ
|
Этот оператор на английском называется pipe, и на русском его называют труба или конвейер. Используется очень часто для перенаправления вывода из одной команды в другую, которая может принимать стандартный вывод. Например:
echo 'Строка с числом 901255323' | grep -E -o '[0-9]+'
Выведет:
901255323
>
Символ > используется для перенаправления вывода в файл, например:
ls -l > dir.txt
В этом примере вывод команды ls -l будет записан в файл dir.txt.
То есть оператор | используется когда вывод передаётся в другую команду, а оператор > используется когда вывод записывается в файл.
Ещё один пример использования сразу обоих операторов:
echo 'Строка с числом 901255323' | grep -E -o '[0-9]+' > num.txt
Результат работы этой последовательности команд будет сохранён в файл num.txt.
Если файл не существует, то он будет создан. Если файл существует, то оператор > полностью удалит его содержимое и запишет новым.
> /dev/null
Это частный случай перенаправления, когда всё из стандартного вывода перенаправляется в псевдоустройство /dev/null. Это означает уничтожение данные. То есть ничего не будет выводиться в стандартный вывод.
>>
Функция оператора >> похожа на > с тем отличием, что оператор >> не удаляет содержимое файла, а дописывает новые данные к уже существующим.
Если файл не существует, то оператор >> создаст его и запишет в него переданные данные.
2>
Оператор 2> перенаправляет стандартный вывод ошибок — standard error (stderr).
Результат выполнения команд и возникшие ошибки выводятся на консоль и может показаться, что это одно и то же. Но на самом деле, это разные типы вывода.
К примеру попытаемся сохранить в файл текст ошибки, возникшей в результате выполнения команды:
ls -l /bin/usr > ls-error.txt
Текст ошибки будет выведен на экран, но файл ls-error.txt окажется пустым.
Дело в том, что нужно различать стандартный вывод и стандартный вывод ошибок. Чтобы перенаправить стандартный вывод в файл используется оператор 2>:
ls -l /bin/usr 2> ls-error.txt
В данном случае ошибка не будет выведена на экран, а будет сохранена в файл ls-error.txt.
Чтобы перенаправить стандартную ошибку, мы должны обратиться к её файловому дескриптору. Программа может выводить любой из нескольких пронумерованных файловых потоков. Первые три из этих файловых потоков называются стандартный ввод, стандартный вывод и стандартный вывод ошибок. Оболочка ссылается на них внутренне как файловые дескрипторы 0, 1 и 2 соответственно. Оболочка обеспечивает запись для перенаправления файлов с использованием номера дескриптора файла. Поскольку стандартная ошибка совпадает с дескриптором файла номер 2, мы можем перенаправить стандартную ошибку с помощью 2>.
Файловый дескриптор «2» помещается непосредственно перед оператором перенаправления, чтобы выполнить перенаправление стандартной ошибки в файл ls-error.txt.
2>&1
Конструкция 2>&1 предназначена для перенаправления стандартного вывода и стандартного вывода ошибок в один поток, который затем может быть перенаправлен в единый файл.
В некоторых случаях мы можем захотеть записать весь вывод команды в один файл. Чтобы сделать это, мы должны одновременно перенаправить как стандартный вывод, так и стандартный вывод ошибок. Есть два способа сделать это. Во-первых, традиционный способ, который работает со старыми версиями оболочки:
ls -l /bin/usr > ls-output.txt 2>&1
Используя этот метод, мы выполняем два перенаправления. Сначала мы перенаправляем стандартный вывод в файл ls-output.txt, а затем перенаправляем дескриптор файла 2 (стандартная вывод ошибок) на дескриптор файла один (стандартный вывод), используя обозначения 2>&1.
Обратите внимание, что порядок перенаправлений является значимым. Перенаправление стандартной ошибки всегда должно происходить после перенаправления стандартного вывода, иначе оно не работает. В приведённом выше примере
>ls-output.txt 2>&1
перенаправляет стандартную ошибку в файл ls-output.txt, но при изменении порядка на
2>&1 >ls-output.txt
стандартная ошибка направлена на экран.
&>
Последние версии bash предоставляют второй, более упрощённый метод для выполнения комбинированного перенаправления 2>&1:
ls -l /bin/usr &> ls-output.txt
В этом примере мы используем одинарную запись &> для перенаправления как стандартного вывода, так и стандартной ошибки в файл ls-output.txt.
&>>
Вы также можете добавить стандартные выходные данные и стандартные потоки ошибок в один файл, например так:
ls -l /bin/usr &>> ls-output.txt
Итак, &> является аналогом 2>&1, а &>> это то же самое, но с перенаправлением вывода в файл.
<
Как мы уже рассмотрели выше, символ > является перенаправлением вывода. Что касается символа <, то он перенаправляет ввод. Используется следующим образом:
КОМАНДА1 < ФАЙЛ1
В этом случае КОМАНДА1 будет выполнена с ФАЙЛ1 в качестве источника ввода вместо клавиатуры, которая является обычным источником стандартного ввода.
Оператор < соответствует использованию | для передачи в программу стандартного ввода. Например, следующие команды являются идентичными:
КОМАНДА1 < ФАЙЛ1 cat ФАЙЛ1 | КОМАНДА1
Ещё один пример, содержимое файла math.txt:
cat math.txt 4*5
Тогда следующие команды идентичны:
bc < math.txt # результат 20 echo '4*5' | bc # результат 20

<<
Оператор << называется here document. С его помощью можно ввести строку состоящую из нескольких строк или присвоить переменной многострочное значение.
Если в консоль ввести
a=строка
и нажать Enter, то переменной a будет присвоено значение «строка» и вновь станет доступно приглашение командной строки, потому что Enter по умолчанию является разделителем, символом новой строки. Из-за этого не получится ввести многострочное значение.
Оператор << (here document) меняет это правило — обозначением для новой строки становится другая последовательность символов. В качестве такого обозначения можно выбрать любой набор символов, единственное условие — этот набор не должен встречаться в водимых данных.
К примеру:
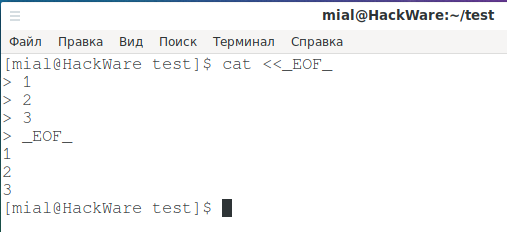
cat <<_EOF_
Данная запись означает, что запущена команда cat, после неё идёт оператор << и последовательность символов _EOF_. Эти символы (_EOF_) + Enter означают, что _EOF_ - становится обозначением начала и конца для многострочных данных. То есть Enter больше не будет означать окончание ввода данных, в качестве обозначения окончания ввода данных будет выступать _EOF_. Вместо этих символов можно выбрать что угодно.
Второй ввод _EOF_ + Enter означает конец многострочных данных. После этого будет выполнена команда, то есть будут выведены введённые цифры:
cat <<_EOF_ 1 2 3 _EOF_
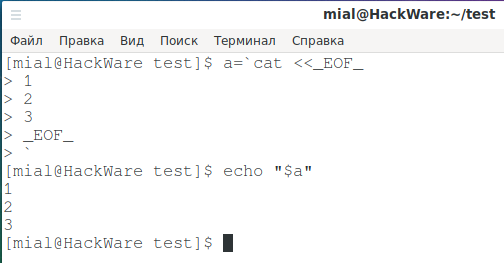
Если вы хотите переменной присвоить многострочное значение, то это можно сделать примерно так:
a=`cat <<_EOF_ 1 2 3 _EOF_ `
Выведем значение переменной:
echo "$a"
Here document это весьма полезная конструкция, к примеру, с её помощью можно делать шаблоны текста, меню, выводимых данных:
#!/bin/bash userName="MiAl (Alex)" site=ZaLinux.ru status=admin cat <<_EOF_ User: $userName Web-site: $site Role: $status _EOF_
Вывод:
User: MiAl (Alex) Web-site: ZaLinux.ru Role: admin

<<<
Оператор <<< называется here string. Он передаёт с правой стороны стандартный ввод. Чтобы было понятно, следующие команды эквивалентны:
wc <<< 'just a string'
1 3 14
echo 'just a string' | wc
1 3 14
Почему << (here document) и <<< (here string) нельзя использовать с переменными
Если мы захотим присвоить переменной значение с помощью рассмотренных операторов и попробуем выполнить:
a <<< 'just a string'
или
a <<< _EOF_
то будет получена ошибка:
bash: a: команда не найдена
Причина в том, что нельзя присвоить значение переменным передав данные в стандартном вводе. Например команда
echo 'just a string' | a
вызовет точно такую же ошибку.
А операторы << (here document) и <<< (here string) передают данные командам в стандартном вводе.
В чём различие << (here document) и <<< (here string)
Различие между этими операторами в том, что << передаёт многострочные данные, которые обрамляются указанной последовательностью символов, а <<< передаёт только строку.
<(КОМАНДА)
Конструкция <(КОМАНДА) называется «подстановка процессов» (Process Substitution). В качестве КОМАНДА может быть одна или более команд с аргументами. Конструкция
<(КОМАНДА)
вернёт имя специального файла, прочитав который можно получить вывод КОМАНДЫ.
К примеру:
echo <(ls -l)
выведет:
/dev/fd/63
Применение данного способа записи и чтения в и из команды показано далее.
>(КОМАНДА)
Это ещё одна форма «подстановки процессов» (Process Substitution):
>(КОМАНДА)
Если используется эта форма, то вместо записи в файл, данные будут переданы на ввод для КОМАНДЫ.
< <(КОМАНДА АРГУМЕНТЫ)
Данная конструкция состоит из двух уже рассмотренных ранее элементов языка Bash:
- <(КОМАНДА АРГУМЕНТЫ)
- <
Как мы только что узнали, <(КОМАНДА АРГУМЕНТЫ) возвращает имя файла из которого нужно считывать результат выполнения КОМАНДЫ. А оператор < передаёт ввод с файла (указанного справа от него) команде на стандартный ввод (указанной слева).
Следующие две команды являются аналогами друг друга:
grep drw < <(ls -l) ls -l | grep drw
Практический пример использования из статьи «Как обработать каждую строку, полученную от команды grep»:
while read -r line ; do
echo " Обрабатывается $line"
# здесь ваш код
done < <(grep xyz abc.txt)
2> >(КОМАНДА) > /dev/null
Эка комбинация, включающая в себя 3 уже рассмотренных элемента:
- 2> означает перенаправление стандартного вывода ошибок (stderr)
- >(КОМАНДА) означает подстановку процессов, в результате стандартный вывод ошибок будет передан для обработки в КОМАНДУ
- > /dev/null означает перенаправления стандартного вывода в /dev/null, то есть фактическое уничтожение стандартного вывода
Пример практического использования:
curl -v 100.19.18.59 2> >(grep -o -i -E '401 Unauthorized') > /dev/null
HTTP заголовки команда cURL выводит в stderr, а команда grep не ищет по stderr. Но если мы хотим искать только по HTTP заголовков (игнорируя HTML код), то мы не может сделать просто перенаправление stderr для слияния со стандартным выводом, то есть не можем 2>&1, поскольку текст страницы может содержать фразу «401 Unauthorized» и мы получим ложное срабатывание. Поэтому мы используем указанную выше конструкцию — стандартный вывод ошибок обрабатывается, стандартный вывод уничтожается.
cat > ФАЙЛ <<_EOF_
Эта конструкция может показаться очень замысловатой, но она состоит из двух уже рассмотренных элементов:
- > (перенаправление вывода в файл)
- << (here document, то есть многострочный ввод)
Рассмотрим пример:
cat > ФАЙЛ <<_EOF_ foo bar bar bar foo foo _EOF_
В результате выполнения этого кода, в ФАЙЛ будут записаны строки
foo bar bar bar foo foo
Причём если ФАЙЛ уже существует, то он будет стёрт и заменён указанным содержимым.
То есть это один из способов сохранения в файл многострочного вывода.
cat >> ФАЙЛ <<_EOF_
Эта конструкция похожа на предыдущую, в ней используются
- >> (перенаправление вывода в файл с дописыванием данных)
- << (here document, то есть многострочный ввод)
В результате выполнения следующего кода:
cat >> ФАЙЛ <<_EOF_ foo bar bar bar foo foo _EOF_
В ФАЙЛ будут сохранены строки:
foo bar bar bar foo foo
Причём если ФАЙЛ уже существует, то он будет дописан.
cat <<_EOF_ > ФАЙЛ
Данная конструкция получает многострочный ввод по стандартному вводу и сохраняет его в файл. То есть это аналог
cat > ФАЙЛ <<_EOF_
в котором просто операторы поменяны местами.
К примеру, в следующем примере:
cat <<_EOF_ > num.txt 12345 67890 1011121314 _EOF_
В файл num.txt будут сохранены строки
12345 67890 1011121314
cat <<_EOF_ >> ФАЙЛ
Эта запись является аналогом
cat >> ФАЙЛ <<_EOF_
Следующим код
cat <<_EOF_ >> num.txt 12345 67890 1011121314 _EOF_
допишет файл num.txt строками
12345 67890 1011121314
Связанные статьи:
- Как в PHP 8 показать все ошибки (73.5%)
- Как создавать диалоговые блоки в интерактивных shell скриптах (53.1%)
- Как в Bash реализовать «Нажмите любую кнопку для продолжения» (53.1%)
- Как в Bash проверить, содержит ли строка подстроку (53.1%)
- Что такое башизм (bashisms) (53.1%)
- Как извлечь часть строки в Bash (RANDOM - 53.1%)
Ошибка
Вмето
'just a string'|wcдолжно быть
echo
'just a string'|wcПриветствую! Совершенно правильное замечание – поправил.
Это в файл и это в файл …так в чем разница?
Приветствую! Замечание справедливое, действительно
не перенаправляет в файл, а всего лишь объединяет потоки вывода ошибок и стандартного вывода в один.
Но «2>&1» зачастую используется в следующей конструкции
которая перенаправляет вывод в файл. Иначе использование «2>&1» не имеет смысла: поскольку на экране вывод ошибок и стандартный вывод отображаются одинаково.
Также объединение вывода ошибок со стандартным выводом может использоваться при передачи данных по конвейеру таким программам как grep, awk, sed если требуется выполнить поиск или другие действия не только с выводимыми данными, но и с выводимыми ошибками.
В статье я поправил описание «2>&1».
>(КОМАНДА)
<(КОМАНДА)
Чё-то не работают эти конструкции
Приветствую! В статье всё написано, вы просто не до конца разобрались. Эти конструкции не используются сами по себе, поскольку, например, «конструкция <(КОМАНДА) вернёт имя специального файла, прочитав который можно получить вывод КОМАНДЫ».
Также в статье сказано:
Пример дан в разделе < <(КОМАНДА АРГУМЕНТЫ).
Допустим, вам хочется какой-то пример с командой ls.
Вывод <(КОМАНДА) нужно передавать в ту команду, которая умеет работать с файлами в качестве ввода, например:
Более практичный пример.
Следующая конструкция
не будет работать. Нужна ещё одна команда, которой будут переданы данные для дальнейшей обработки.
Например, следующая команда покажет все файлы в текущей директории, которые начинаются с точки:
Кстати, команду можно чуть упростить до
Смысл конструкции <(КОМАНДА) в том, что можно передать вывод в конструкцию «while read». А ещё в одну команду можно передать вывод сразу из нескольких команд. Это полезно при условии, что команда может работать сразу с несколькими файлами в качестве ввода. Например:
Пример с >(КОМАНДА):
В этой конструкции вывод ls будет передан команде grep и она сохранит строки с буквой «w» в файл w.txt.