Фильтрация невалидных UTF-8 символов
Файлы, которые кроме обычных символов содержат неверные с точки зрения UTF-8 символы, вызывают проблему как при обработке их утилитами, так и при открытии в текстовых редакторах.
Пример ошибки в Python 3 при попытке обработать файл с не UTF-8 символами:
[-] Exception as following:
Traceback (most recent call last):
File "/home/mial/bin/pydictor/lib/fun/decorator.py", line 21, in magic
for item in unique(func()):
File "/home/mial/bin/pydictor/lib/fun/fun.py", line 30, in unique
for item in seq:
File "/home/mial/bin/pydictor/tools/uniqifer.py", line 31, in uniqifer
for item in o_f.readlines():
File "/usr/lib/python3.9/codecs.py", line 322, in decode
(result, consumed) = self._buffer_decode(data, self.errors, final)
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xf1 in position 933: invalid continuation byte
None
Пример ошибки в Perl:
Malformed UTF-8 character (fatal)
Пример сообщения при попытке открыть в текстовом редакторе gedit:
Открытый файл содержит недопустимые символы. Дальнейшее редактирование может повредить документ. Можете выбрать другую кодировку и попытаться снова.
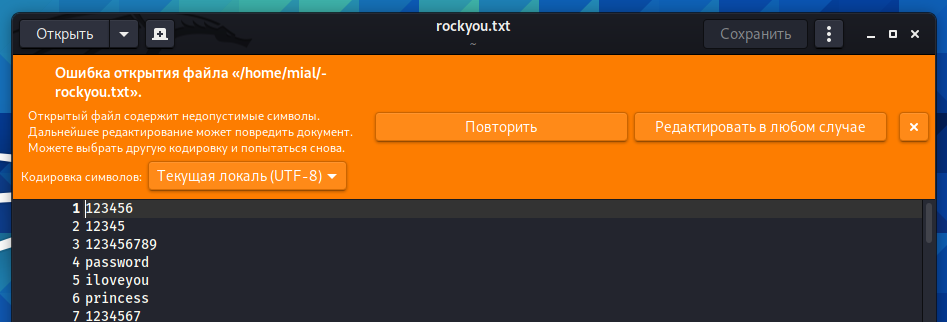
Как найти не UTF-8 символы в файле
Чтобы обнаружить строки с нечитаемыми символами используйте команду вида:
grep -axv '.*' ФАЙЛ
В локали UTF-8, вы получите строки, содержащие как минимум одну недопустимую последовательность UTF-8 (по крайней мере, это работает с GNU Grep).

Смотрите также: Регулярные выражения и команда grep
Как можно увидеть на скриншоте, действительно имеются странные символы.
Проверяя содержимое этих файлов вручную, вы также обнаружите в них какие-то странные символы.
Есть ли способ убрать их все автоматически?
Что такое символы, отличные от UTF-8?
Можно подумать, что все символы в правильно сформированной строке UTF-8 являются символами UTF-8 (фактически Unicode)! Некоторые из них имеют кодировку UTF-8 в несколько последовательных байтов.
Но на самом деле существуют искажённый символы UTF-8. Это означает, что появился байт, который не может быть частью допустимого файла UTF-8. Это не сложно; это может быть байт 0xC0 или 0xC1, или 0xF5..0xFF, или проблема последовательности с байтами, которые в противном случае были бы действительными.
Как автоматически удалить искажённые символы (не UTF-8) из файла
Эта команда:
iconv -f utf-8 -t utf-8 -c ФАЙЛ.txt
очистит ваш файл UTF-8, пропустив все недопустимые символы.
- -f - исходный формат
- -t - целевой формат
- -c - пропускает любую недопустимую последовательность
В Mac используйте команду:
iconv -f utf-8 -t utf-8 -c file.txt
То есть между 'f' и '8' нужен дефис.
По умолчанию очищенные данные будут выведены в стандартный вывод. Поэтому используйте одну из следующих команд для сохранения результатов в новый файл:
iconv -f utf-8 -t utf-8 -c ФАЙЛ.txt -o НОВЫЙ_ФАЙЛ.txt iconv -f utf-8 -t utf-8 -c ФАЙЛ.txt > НОВЫЙ_ФАЙЛ.txt
Примеры:
iconv -f utf-8 -t utf-8 -c ~/rockyou.txt > ~/rockyou_clean.txt iconv -f utf-8 -t utf-8 -c ~/rockyou.txt -o ~/rockyou_clean.txt
Связанные статьи:
- Как определить кодировку файла или строки. Как конвертировать файлы в кодировку UTF-8 в Linux (49.1%)
- Примеры команды Sed (33.7%)
- Уроки по Awk (33.7%)
- Как отфильтровать текст, находящийся между двумя определёнными строками (33.7%)
- Как добавить строку в начало или в конец каждой строчки (33.7%)
- Ошибка «Failed to talk to init daemon.» (РЕШЕНО) (RANDOM - 1%)