Источник: перевод фрагмента книги «Barry J. Grundy. The Law Enforcement and Forensic Examiner’s Introduction to Linux».
Если вы начинающий пользователь Linux и вы ничего не знаете про блочные устройства, то начните со статьи Структура директорий Linux. Важные файлы Linux, а именно с раздела «Где в Linux диски C, D, E?».
dd — это самая простая утилита для копирования данных, которая поставляется со стандартным дистрибутивом GNU/Linux. Без сомнения, есть несколько лучших инструментов для работы с образами для использования с Linux, но dd — это старый резерв. В следующих статьях мы рассмотрим некоторые из наиболее ориентированных на криминалистику инструментов визуализации, но изучение dd важно по той же причине, что и изучение vi. Как и vi, вы обязательно найдёте dd практически на любой машине Unix, с которой вы можете столкнуться. Если же говорить об обычных простейших операциях, таких как создание копии диска, раздела или восстановление из копии, то программы dd вполне достаточно.
Команда dd скопирует каждый бит из доступных для ядра областей носителя в место назначения по вашему выбору (физическое устройство или файл). При использовании dd следует помнить о нескольких концепциях. Некоторые из этих концепций также применимы к другим инструментам криминалистической работы с дисками, которые мы рассмотрим. В очень простой форме команда dd выглядит так:
dd if=/dev/sdd of=/path/to/evidence.raw bs=512
Входной файл указывается с опцией if=, это исходный носитель образ (копию) которого мы создаём в файле.
Для создания образа диска (/dev/sdx) мы можем использовать имя для всего устройства.
Для создания образа раздела (/dev/sdx#) мы можем использовать имя устройства и номер раздела для создания образа одного раздела/файловой системы. # - это номер раздела (например, возвращаемый командой fdisk -l).
Входной файл может быть и образом диска, об этом ниже.
Выходной файл указывается с of=, это место назначения где мы размещаем образ/копию: of=/ПУТЬ/К/ФАЙЛУ.raw
Вывод может быть файлом (как указано выше). Это чаще всего.
Выход может быть физическим устройством. Это часто называют «клонированием». Также запись на физическое устройство можно применять для восстановления данных из резервной копии или для создания загрузочной флешки из образа ISO диска.
Размер блока устройства для клонирования указывается с необязательной опцией bs=. Обычно этим занимается ядро, поэтому данную опцию указывать необязательно, поскольку размер блока определяется автоматически.
Индикация прогресса: status=progress
Эта опция обеспечивает удобную строку состояния обновления, которая показывает прогресс создания образа. Относительно недавнее дополнение к опциям dd.
Также есть опции, которые часто используются, чтобы избежать проблем в случае плохих секторов на диске: conv=noerror,sync
Эта опция указывает dd не обрывать работу, если встретились секторы с ошибками И при этом непрочитанные места будут заполнены нулями в создаваемом образе. Заполнение сохраняет правильные смещения в любых данных на файловой системе, что может сохранить её работоспособность. Но на самом деле это не самый лучший вариант — при наличии проблемных секторов нужно использовать специализированные инструменты.
Мы создадим новый каталог с именем images в нашем каталоге case1. Здесь мы будем хранить рабочие копии наших образов. Обычно образы создаются либо непосредственно на большем диске, либо на том сетевого хранилища, который используется для хранения исходных копий. Это будет зависеть от вашей конкретной политики.
В этом случае, для иллюстрации, мы разместим образ непосредственно в нашем каталоге case1/images. Я предпочитаю хранить образы отдельно, поскольку это позволяет защитить каталог с помощью атрибутов, которые предотвращают изменение или удаление файлов образов нашей рабочей копии после завершения процесса создания образов. Однако это личное предпочтение.
Чтобы наша командная строка dd была короче, мы перейдём в каталог case1/images и запишем здесь наш выходной файл. Без необходимости указывать каталог (мы пишем в текущий каталог), это сделает командную строку короче и удобнее для чтения.
mkdir images cd images pwd /mnt/evidence/case1/images dd if=/dev/sdd of=case1.disk1.raw bs=512 79975662080 bytes (80 GB, 74 GiB) copied, 2168 s, 36.9 MB/sk^[^[ 156250000+0 records in 156250000+0 records out 80000000000 bytes (80 GB, 75 GiB) copied, 2169.67 s, 36.9 MB/s
Эта команда принимает ваше дисковое устройство /dev/sdd в качестве входного файла if и записывает выходной файл с именем case1.disk1.raw в текущий каталог /mnt/evidence/case1/images. Опция bs определяет размер блока, но она не требуется для большинства блочных устройств (жёстких дисков и т. д.), поскольку ядро Linux обрабатывает фактический размер блока. Она добавлена здесь для иллюстрации, так как может быть полезна во многих ситуациях (обсуждается позже). Повторите указанную выше команду с status=progress, чтобы следить за обновлениями о том, насколько близко к завершению создание образа.
Использование dd создаёт точную копию файла физического устройства. Сюда входят все файлы и незанятое пространство. Мы не просто копируем логическую файловую структуру. В отличие от многих криминалистических инструментов создания образов, dd не заполняет образ какими-либо собственными данными или информацией. Это простое копирование битового потока от начала до конца. Как мы увидим позже, у этого есть ряд преимуществ.
Вы можете видеть из наших выходных данных выше, что dd прочитал такое же количество записей (в данном случае 512-байтовых блоков), что и количество секторов для этого диска, ранее сообщённое hdparm -I, 156250000. Чтобы проверить ваш образ, мы можем сделать следующее: Можно проверить хеш исходного устройства (/dev/sdd) и сравнить его с хешем только что полученный файл образа.
sha1sum /dev/sdd ddddda4252d1adeffa267636b1ae0fbf40c9d3b3 /dev/sdd sha1sum case1.disk1.raw ddddda4252d1adeffa267636b1ae0fbf40c9d3b3 case1.disk1.raw
Вы можете увидеть совпадение двух хешей, что подтверждает наш образ как истинную копию исходного диска.
Это самый простой вариант использования dd.
dd и разбивка образов на файлы
В цифровой криминалистике стало обычной практикой разделять выходные данные образов на несколько файлов. Это делается по ряду причин: либо для архивирования, либо для использования в другой программе. Сначала мы обсудим самостоятельное использование split, а затем вместе с dd для разделения «на лету».
Связанная статья: Инструкция по использованию split
Например, у нас есть образ размером 80 ГБ, и теперь мы хотим разделить его на части по 4 ГБ, чтобы их можно было записать на другой носитель. Или, если вы хотите хранить файлы в файловой системе с ограничениями на размер файла и вам нужен определённый размер, вы можете разделить образ на более мелкие разделы.
Для этого мы используем команду split.
Команда split обычно работает со строками ввода (то есть из текстового файла). Но если мы используем параметр -b, мы заставляем split рассматривать файл как двоичный ввод, а строки игнорируются. Мы можем указать размер файлов, которые мы хотим, вместе с префиксом, который мы хотим для выходных файлов. split также может использовать параметр -d, чтобы дать нам числовую нумерацию (*.01 , *.02 , *.03 и т. д.) для выходных файлов, а не алфавитную, которая применяется по умолчанию (*.aa , *.ab , *.ac, и т.д.). Параметр -a указывает длину суффикса. Команда выглядит так:
split -d -a ЧИСЛО -b РАЗМЕРG ФАЙЛ_ДЛЯ_РАЗБИВКИ ПРЕФИКС_ВЫХОДНЫХ_ФАЙЛОВ
где ЧИСЛО — длина расширения (или суффикса), которое мы будем использовать, а РАЗМЕР — это размер результирующих файлов с модификатором единиц (K, M, G и т. д.). Наш образ /dev/sdd мы можем разделить его на файлы размером 4 ГБ с помощью следующей команды (размер последнего файла будет соответствовать оставшейся части тома, если он не является точно кратным выбранному вами размеру):
split -d -a 3 -b 4G case1.disk1.raw case1.disk1.split.
Это приведёт к созданию группы файлов (размером 4 ГБ), каждый из которых будет назван префиксом case1.split1, как указано в команде, за которым следует .000, .001, .002 и т. д. Параметр -a с 3 указывает, что мы хотим, чтобы расширение было не менее 3 цифр. Без -a 3 наши файлы будут называться .000 , .001 , .002 и т. д. Использование трёх цифр обеспечивает согласованность с другими инструментами — некоторые наборы программного обеспечения для судебной экспертизы не распознают разделённые изображения, имена которых имеют расширение, отличное от трёх символов. Обратите внимание на конечную точку в имени нашего выходного файла. Мы делаем это так, чтобы суффикс добавлялся как расширение файла, а не как строка суффикса, добавляемая в конец строки имени.
Процесс можно повернуть вспять. Если мы хотим повторно собрать образ из разделённых частей, мы можем использовать команду cat и перенаправить вывод в новый файл. Помните, что cat просто выводит указанные файлы на стандартный вывод. Если вы перенаправите этот вывод, файлы будут собраны в один.
cat case1.disk1.split* > case1.disk1.new.raw
В приведённой выше команде мы повторно собрали разделённые части в новый файл образа размером 80 ГБ. Исходные разделённые файлы не удаляются, поэтому приведённая выше команда существенно удвоит ваши требования к свободному месту на диске, если вы выполняете запись в одно и то же смонтированное устройство/каталог.
Эту же команду cat можно использовать для проверки хеша результирующих разделов образа путём передачи по конвейеру всех частей образа с помощью символа | (труба) в нашу команду хеширования:
cat case1.disk1.split* | sha1sum ddddda4252d1adeffa267636b1ae0fbf40c9d3b3 -
Ещё раз видим, что хеш остаётся неизменным. Знак - в конце вывода означает, что мы взяли ввод со стандартного ввода, а не из файла или устройства. В приведённой выше команде sha1sum получает входные данные напрямую от команды cat через трубу.
Другой способ создания многосегментных образов — разделение образа по мере его создания (непосредственно с помощью команды dd). По сути, это разделение «на лету», о котором мы упоминали ранее. Мы делаем это, передавая вывод команды dd прямо в split, опуская часть of= команды dd. Предполагая, что наш целевой диск — /dev/sdd, мы должны использовать команду:
dd if=/dev/sdd | split -d -a 3 -b 4G - case1.disk1.split. 156250000+0 records in 156250000+0 records out 80000000000 bytes (80 GB, 75 GiB) copied, 1146.87 s, 69.8 MB/s
Здесь вместо того, чтобы указывать имя файла, который будет разделен в команде split, мы даём простое - (тире) (после 4G, где у нас было имя входного файла в нашем предыдущем примере). Единственное тире — это дескриптор, означающий «стандартный ввод». Другими словами, команда dd выдаёт поток данных в стандартный вывод (так как не указан файл для сохранения), а программа split принимает этот поток байтов на стандартный ввод, а не из файла. Любые параметры, которые вы хотите передать в dd (размер блока, количество и т. д. идут перед трубой). Приведённый выше вывод показывает, что уже знакомое количество секторов является правильным для диска, который мы создаём (156250000).
Когда у нас есть образ, тот же метод с использованием cat позволит нам собрать его для хеширования или анализа, как мы это сделали с разделёнными образами выше.
Для практики вы можете использовать небольшой USB-накопитель, если он у вас есть, и попробовать этот метод на этом устройстве, разделив его на разумное количество частей. Вы можете использовать любой образец диска, не забудьте заменить наш узел устройства в следующей команде на /dev/sdx (где x — это ваш флэш-накопитель или другой носитель). Сначала получите хэш, чтобы вы могли сравнить разделённые файлы и оригинал и убедиться, что разделение ничего не меняет.
В следующем примере используется USB-накопитель ёмкостью 2 ГБ, который произвольно разделен на разделы размером 512 МБ. Следуйте командам и экспериментируйте с параметрами, наблюдая за изменениями в конечном результате. Это лучший способ учиться. Мы начнём с идентификации флэш-диска с помощью lsscsi, как только он будет подключён (вывод сокращён для удобства чтения):
lsscsi sha1sum /dev/sdb dd if=/dev/sdb | split -d -a3 -b512M - thumb.split. ls -lh thumb.split.*| sha1sum cat thumb.split.*| sha1sum
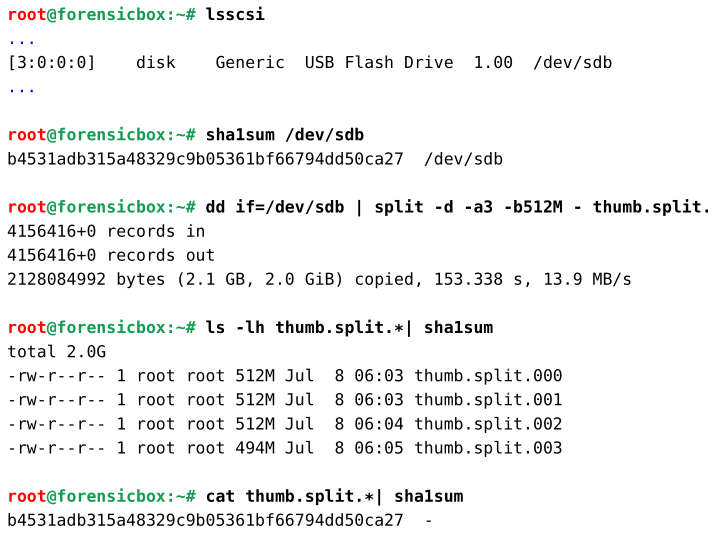
Глядя на вывод вышеуказанных команд, мы сначала видим, что подключенный флэш-накопитель идентифицируется как универсальный USB-накопитель. Затем мы на лету хэшируем устройство, образ и разбиваем его с помощью dd, а затем проверяем хеш. Мы находим один и тот же хеш для диска, для разделённых образов, «скомпонованных» вместе, и для вновь собранного образа.
Как записать образ на диск
С помощью программы dd можно записать образ диска на физический носитель. В качестве образа диска может быть как полученный с помощью dd файл, так и ISO образ, например, с установочным диском. Таким способом можно записать скаченный .iso файл на флешку и она станет загрузочной. При этом не нужно выполнять какие-либо дополнительные действия — всё необходимо для загрузки с флешки уже будет записано на ней.
В качестве входного файла (опция if) укажите путь до .iso в качестве устройства записи (of) укажите название флешки вида /dev/*, например:
dd if=linux_installer.iso of=/dev/sdd
Вам не нужно беспокоится, если размер образа не совпадает с ёмкостью флешки — она в любом случае будет рабочей. Конечно же, объём USB флешки или диска должен быть достаточным, чтобы на него уместился ISO образ.
Как клонировать диск на другой диск
С помощью программы dd можно полностью клонировать содержимое одного устройства на другое:
dd if=/dev/sdc of=/dev/sdd
Если размер устройств не совпадает, то вы можете получить неожиданный результат. То есть выбирайте для клонирования диски одинакового размера.
Связанные статьи:
- Как восстановить работоспособность USB диска/флешки после записи ISO или установки ОС (РЕШЕНО) (53.6%)
- Как в Linux подключить новый диск, разметить и отформатировать разделы (52.2%)
- Как передавать файлы между Android и Linux (51.5%)
- Какие есть полезные инструменты с интерфейсом командной строки для системных администраторов Linux (50%)
- PhotoRec: восстановление удалённых и потерянных фотографий и файлов на картах памяти и жёстких дисках (50%)
- Инструкция по использованию команды htop для интерактивного просмотра процессов в Linux (RANDOM - 22.1%)